


双重乘法 — v5的诞生
Lifelog — A Mythology-Driven Devlog
·
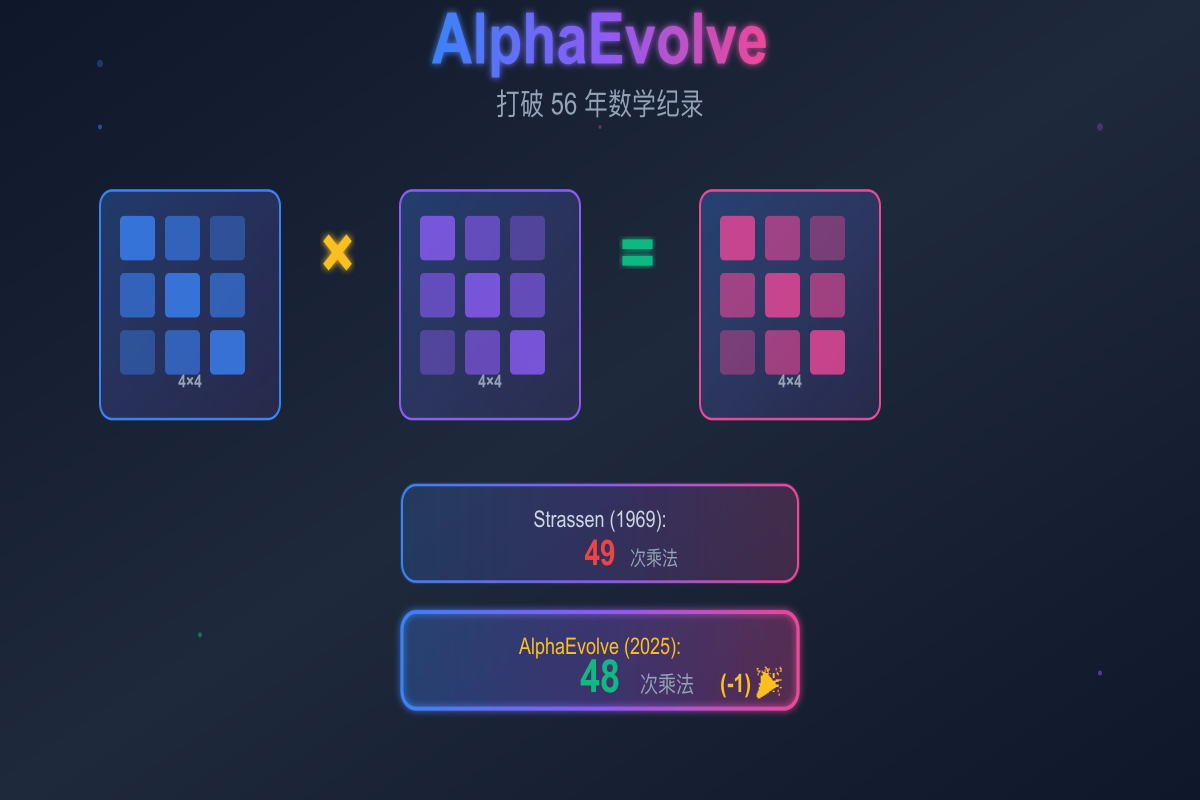
AlphaEvolve:AI 打破 56 年数学纪录,发现更快的矩阵乘法算法
Micropaper
·

模块化:在Blackwell上的矩阵乘法:第4部分 - 打破SOTA
Modular Blog
·

模块化:Blackwell上的矩阵乘法:第三部分 - 达到85%最先进性能的优化
Modular Blog
·

模块化:Blackwell上的矩阵乘法:第二部分 - 利用硬件特性优化矩阵乘法
Modular Blog
·

模块化:在Nvidia Blackwell上的矩阵乘法:第一部分 - 介绍
Modular Blog
·

创建简单计算器作为我的第一个项目
DEV Community
·

