
在Triton中实现矩阵乘法及L2缓存优化
内容提要
本文介绍了在Triton中实现矩阵乘法的方法,并进行了L2缓存优化。通过矩阵分块和利用快速的SRAM,减少对慢速DRAM的访问,从而显著提高性能。同时,优化L2缓存的使用,确保相邻线程共享数据,进一步提升计算效率。文中还提供了完整的Triton代码示例,以帮助读者理解实现过程。
关键要点
-
矩阵乘法是一个简单但难以优化的操作,涉及到两个矩阵的乘积计算。
-
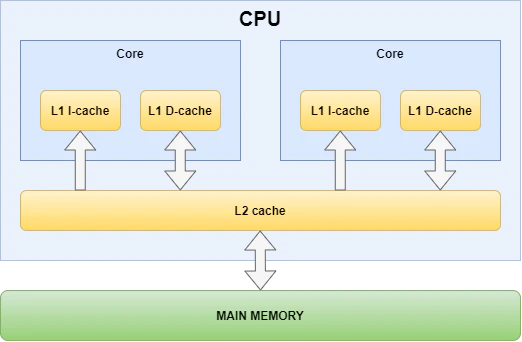
GPU具有内存层次结构,DRAM速度慢但容量大,而SRAM速度快但容量小,优化内存访问是GPU编程的关键。
-
通过将矩阵分块并利用SRAM,可以减少对DRAM的访问,从而提高性能。
-
在Triton中,程序需要显式指定内存中的数据位置,使用指针来加载矩阵块。
-
L2缓存的使用效率对GPU性能至关重要,高L2缓存命中率可以显著提高吞吐量。
-
通过对程序ID进行重新排序,可以提高内存访问的局部性,从而优化L2缓存的使用。
-
提供了完整的Triton代码示例,展示了如何实现矩阵乘法及其优化过程。
延伸解读
GPU内存层次结构的重要性
在GPU编程中,理解内存层次结构至关重要。DRAM虽然容量大,但访问速度慢,而SRAM速度快但容量小。优化内存访问可以显著提高矩阵乘法的性能,尤其是在处理大规模数据时。通过将数据加载到SRAM中并减少对DRAM的访问,可以有效降低延迟,提升计算效率。
L2缓存优化的实践意义
L2缓存的使用效率直接影响GPU的吞吐量。通过合理的程序ID重排序,可以提高内存访问的局部性,从而增加L2缓存的命中率。这种优化在处理大矩阵时尤为重要,因为它能显著减少内存带宽的消耗,提升整体性能。
Triton编程的挑战与优势
使用Triton进行GPU编程时,开发者需要显式指定内存中的数据位置,这虽然增加了编程的复杂性,但也提供了更高的灵活性和控制力。通过手动管理内存访问,开发者能够更好地优化性能,尤其是在矩阵乘法等计算密集型任务中。
延伸问答
在Triton中如何实现矩阵乘法?
在Triton中实现矩阵乘法需要将矩阵分块,利用SRAM加载子块进行计算,并使用指针显式指定内存中的数据位置。
L2缓存优化在GPU编程中有什么重要性?
L2缓存优化可以显著提高GPU的吞吐量,因为高L2缓存命中率减少了对慢速DRAM的访问,从而降低延迟。
如何通过矩阵分块提高矩阵乘法的性能?
通过将矩阵分块并利用SRAM,可以减少对DRAM的访问,从而提高性能,避免了大量的内存流量。
Triton中如何处理内存地址计算?
在Triton中,程序需要手动计算每个元素的内存地址,使用指针和步幅来加载矩阵块。
什么是程序ID重新排序,为什么要使用它?
程序ID重新排序是为了提高内存访问的局部性,使得相邻线程能够共享数据,从而优化L2缓存的使用。
在Triton中实现矩阵乘法的完整代码示例是什么?
文章中提供了完整的Triton代码示例,展示了如何实现矩阵乘法及其优化过程,包括内存管理和L2缓存优化。
