
如果今天这篇注意力机制的帖子看不懂的话,就...可以重读大一了
dotNET跨平台
·

模块化:在Blackwell上的矩阵乘法:第4部分 - 打破SOTA
Modular Blog
·

7个加速数值计算的NumPy技巧
MachineLearningMastery.com
·

模块化:Blackwell上的矩阵乘法:第三部分 - 达到85%最先进性能的优化
Modular Blog
·

模块化:Blackwell上的矩阵乘法:第二部分 - 利用硬件特性优化矩阵乘法
Modular Blog
·

模块化:在Nvidia Blackwell上的矩阵乘法:第一部分 - 介绍
Modular Blog
·

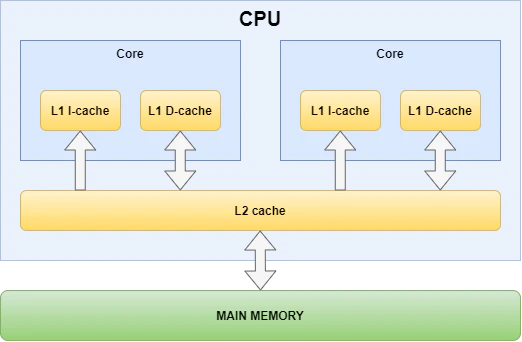
演讲:利用现代架构最大化CPU上的深度学习性能
InfoQ
·

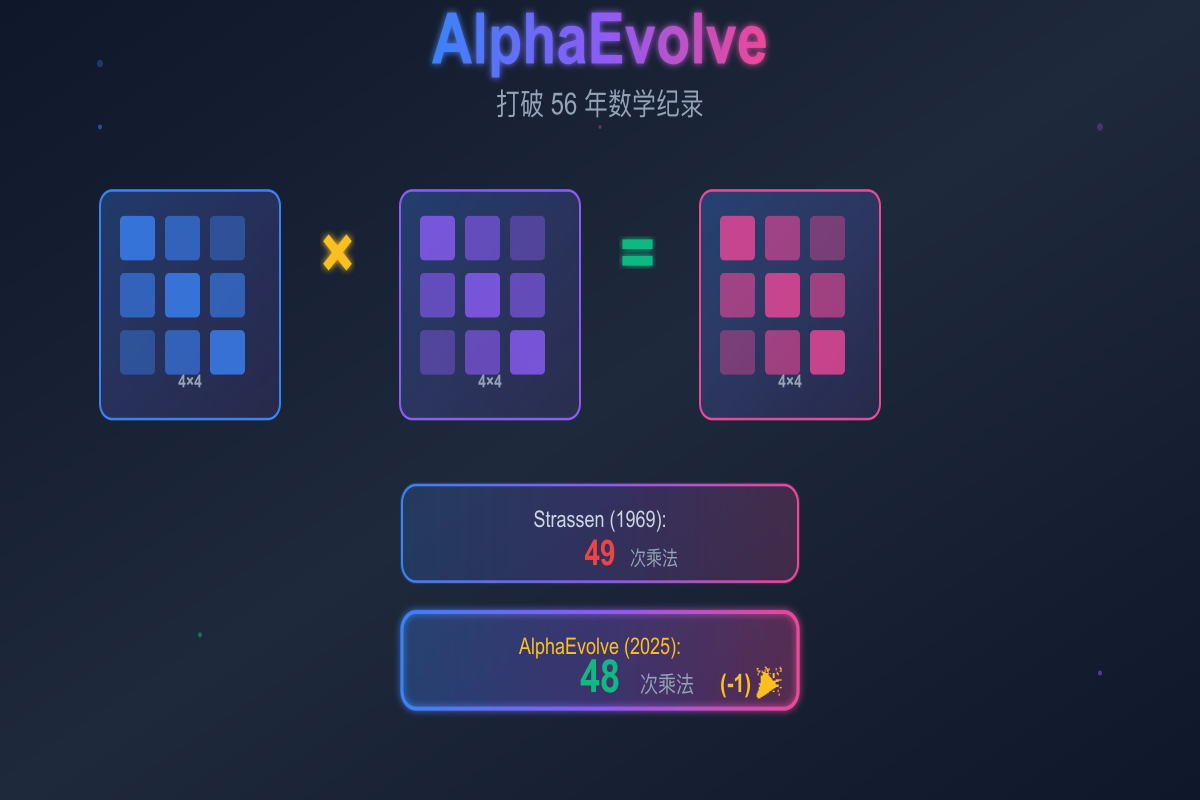
认识AlphaEvolve,谷歌的人工智能,它能够自我编写代码,并且刚刚节省了数百万的计算成本
DEV Community
·