





理解神经网络中的Softmax和交叉熵
DEV Community
·

在大词汇量语言模型中减少损失
Apple Machine Learning Research
·

机器学习中对数的介绍与Python应用
MachineLearningMastery.com
·

数学 + Python = 爱
DEV Community
·

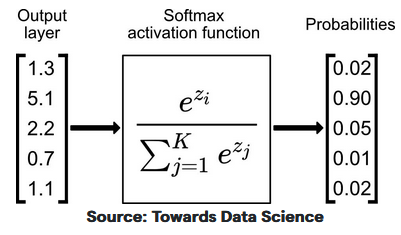
常用激活函数和损失函数
kirito的博客
·
