动作捕捉技术迎来变革,字节跳动推出的DreamActor-M1框架能够高质量生成一致的人体动画,表现出色,可能取代传统动捕技术。
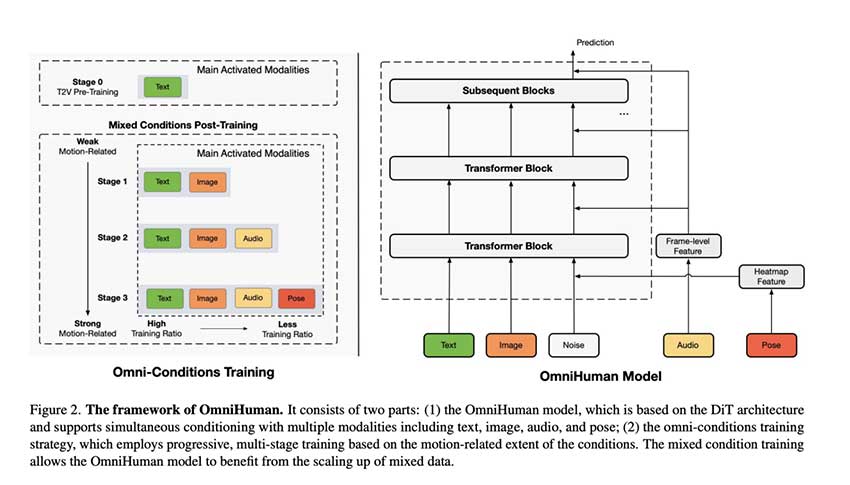
OmniHuman-1是字节跳动推出的基于扩散变换器的AI模型,能够从单一图像生成逼真的人体动画。该模型结合多模态输入,支持音频和视频驱动,适应不同身体比例,提升动作真实感,克服了传统模型的局限性,表现出色,标志着AI人体动画的重大进步。
本文介绍了多种基于扩散模型的人体动画生成方法,如“Dancing Avatar”、“FaceTalk”、“DREAM-Talk”、“VLOGGER”、“AniPortrait”、“LoopAnimate”、“UniAnimate”和“CyberHost”。这些方法利用音频、文本和图像输入生成高质量动态视频,提升了面部表情、姿势多样性和时间一致性,展现了在视频编辑和个性化应用中的潜力。
本文介绍了AvatarGen方法,该方法利用2D图像生成高保真度可控人体动画。通过结合3D高斯分布点技术,显著提高了训练和推理速度,并在多视角视频中实现高质量重建。此外,研究提出的新型流程有效解决了多视角方法在密切交互人群姿态估计中的困难,提升了鲁棒性和精度。实验结果表明,该方法在几何和外观重建上达到了先进水平。
完成下面两步后,将自动完成登录并继续当前操作。