
字节跳动推出 OmniHuman-1:基于单一人体图像和运动信号生成人体视频的端到端多模态框架
内容提要
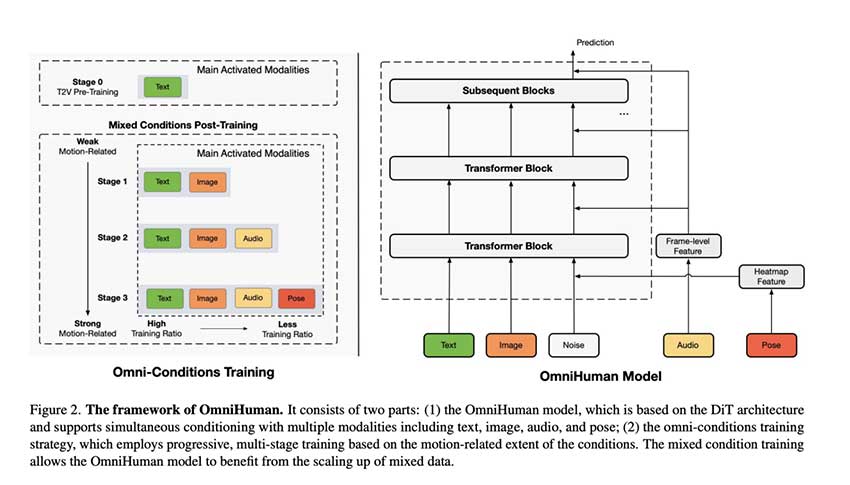
OmniHuman-1是字节跳动推出的基于扩散变换器的AI模型,能够从单一图像生成逼真的人体动画。该模型结合多模态输入,支持音频和视频驱动,适应不同身体比例,提升动作真实感,克服了传统模型的局限性,表现出色,标志着AI人体动画的重大进步。
关键要点
-
OmniHuman-1是字节跳动推出的基于扩散变换器的AI模型,能够从单一图像生成逼真的人体动画。
-
现有模型在动作逼真度、适应性和可扩展性方面存在限制,难以生成流畅的肢体动作。
-
OmniHuman-1结合多模态输入,支持音频和视频驱动,适应不同身体比例,提升动作真实感。
-
该模型采用扩散变换器架构,整合多种运动相关条件,增强视频生成能力。
-
OmniHuman-1支持多种形式的动作输入,包括音频驱动、视频驱动和多模态融合。
-
模型在多个指标上表现出色,如唇语同步精度、Fréchet Video Distance和手势表现力。
-
OmniHuman-1能够适应不同的身体比例和长宽比,具有明显优势。
-
该模型拓宽了创意应用领域,支持卡通、风格化和拟人化的角色动画。
-
OmniHuman-1代表了人工智能驱动的人体动画的重大进步,为虚拟影响者、数字化身和游戏开发提供了重要工具。
延伸解读
OmniHuman-1的技术优势
OmniHuman-1采用扩散变换器架构,结合多模态输入,显著提升了动作生成的真实感和适应性。与传统模型相比,它能够处理更复杂的运动数据,支持音频和视频驱动,适应不同身体比例,拓宽了应用场景。
应用前景与创意潜力
OmniHuman-1不仅限于生成逼真的动画,还支持卡通和风格化角色的创作。这使得它在虚拟影响者、游戏开发和数字故事等领域具有广泛的应用潜力,推动了创意产业的发展。
面临的挑战与局限性
尽管OmniHuman-1在多个指标上表现出色,但仍需关注其在特定场景下的表现。模型的训练依赖于多样化的数据输入,若数据质量不足,可能影响生成效果。因此,数据的选择与处理仍是关键。
延伸问答
OmniHuman-1是什么类型的AI模型?
OmniHuman-1是字节跳动推出的基于扩散变换器的AI模型,能够从单一图像生成逼真的人体动画。
OmniHuman-1如何提升动作真实感?
OmniHuman-1结合多模态输入,支持音频和视频驱动,适应不同身体比例,从而提升动作真实感。
OmniHuman-1与传统模型相比有什么优势?
OmniHuman-1在动作逼真度、适应性和可扩展性方面具有明显优势,能够生成流畅的肢体动作。
OmniHuman-1支持哪些类型的动作输入?
OmniHuman-1支持音频驱动、视频驱动和多模态融合的动作输入。
OmniHuman-1在性能测试中表现如何?
OmniHuman-1在唇语同步精度、Fréchet Video Distance和手势表现力等多个指标上表现出色。
OmniHuman-1的应用领域有哪些?
OmniHuman-1可用于虚拟影响者、数字化身、游戏开发和人工智能辅助电影制作等领域。
