

人工智能论文评审:通过人类反馈训练语言模型以遵循指令(InstructGPT)
freeCodeCamp.org
·
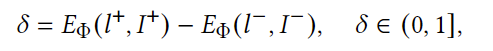
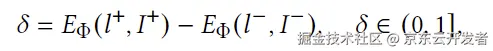
京东零售广告创意:统一的布局生成和评估模型
京东科技开发者
·

小猫都能懂的大模型原理 5 - 后训练
UsubeniFantasy
·

如何在大型语言模型中避免幻觉?
DEV Community
·


基于人类反馈的强化学习(RLHF)
DEV Community
·
