本研究探讨了大语言模型(LLMs)在战略推理中的表现,发现人类启发的认知结构能够提高LLM代理与人类行为的一致性,但代理设计的复杂性与人类相似性之间的关系是非线性的。
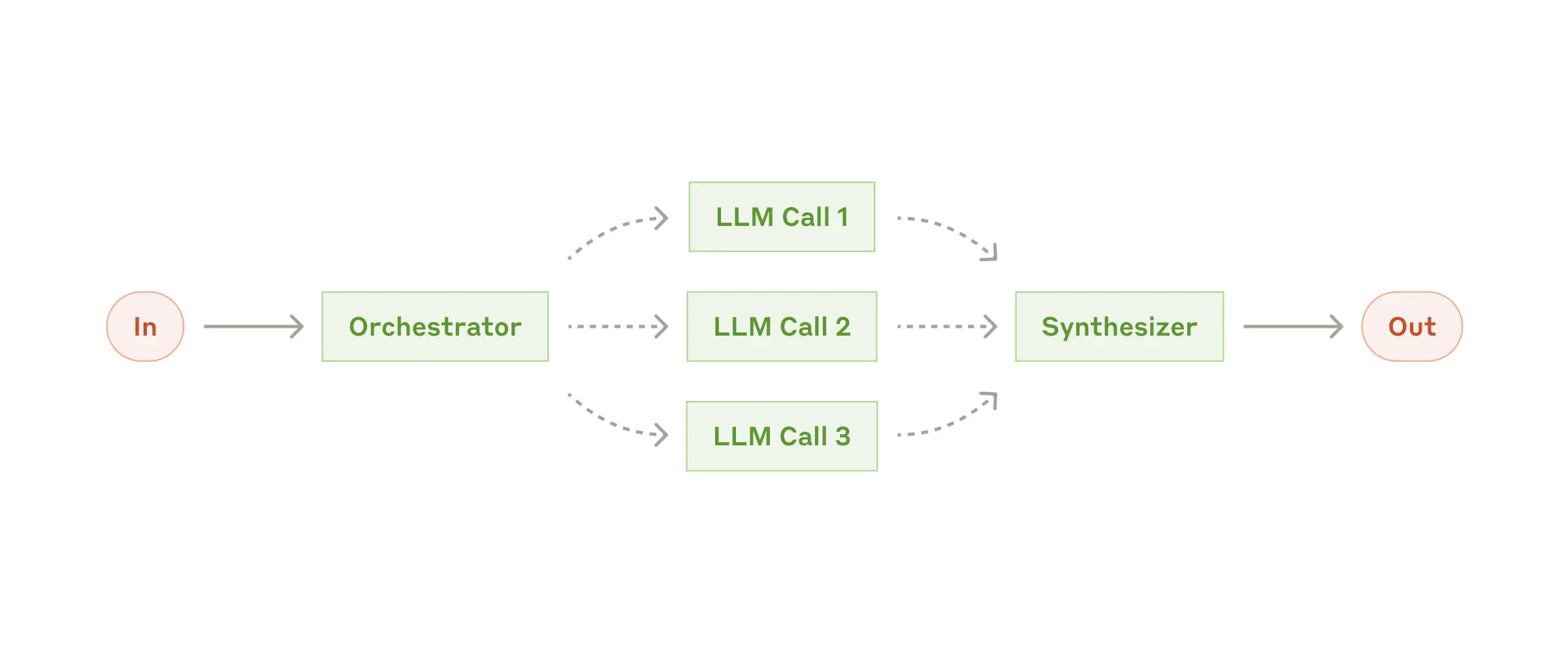
最近关于代理设计的讨论强调成功的代理软件需在自主性与结构性之间取得平衡。LlamaIndex的工作流系统通过事件驱动连接执行步骤,优化代理设计,提升可靠性与灵活性。建议在明确流程时使用结构,而在处理非结构化数据时给予自主权。
在构建大型语言模型(LLM)代理时,成功的实现通常采用简单的可组合模式,而非复杂框架。代理可以是自主系统或遵循预定义工作流程的系统。开发者应优先考虑简单解决方案,复杂性仅在必要时增加。有效的代理设计应保持简单性、透明性,并提供清晰的工具文档。成功的关键在于根据需求构建合适的系统,而非追求复杂性。
一项新的研究发现,当前的AI代理评估和基准测试存在缺陷,阻碍了其在实际应用中的有效性。研究人员提出了解决这些问题的方法,认为需要重新思考基准测试的做法。AI代理评估需要控制成本,联合优化准确性和成本可以获得更好的代理设计。模型开发者和下游开发者有不同的基准测试需求,代理基准测试可以提供捷径,但代理评估缺乏标准化和可重复性。尽管如此,公司仍然希望在应用中使用代理。
研究介绍了AucArena模拟环境,用于评估大型语言模型在竞争环境中的表现。LLMs展示了参与竞拍所需的技能,但个体能力存在变异性。文章强调了LLM代理设计的进一步提高和模拟环境在测试和改进代理体系结构中的重要作用。
研究介绍了AucArena,用于评估LLMs在竞争环境中的表现。LLMs展示了参与竞拍所需的技能,但个体能力存在变异性。即使是最先进的模型(GPT-4)有时也会被基准线和人类代理超越。LLMs代理模拟复杂社交动态的潜力巨大,但需要进一步提高代理设计和模拟环境的测试和改进。
本文介绍了一种新型模拟环境AucArena,用于评估大型语言模型在竞争环境中的表现。LLMs在竞拍中展示了许多技能,但个体能力存在较大变异性。即使是最先进的模型GPT-4有时也会被启发式基准线和人类代理超越。作者认为,LLMs代理模拟复杂社交动态的潜力巨大,但需要进一步提高代理设计和模拟环境的测试和改进。
该文介绍了大型语言模型(LLMs)在竞争环境中展示高级推理技能的能力,并介绍了评估LLMs的新型模拟环境AucArena。研究发现,LLMs可以展示参与竞拍所需的许多技能,但个体能力存在变异性。进一步提高LLM代理设计和模拟环境在测试和改进代理体系结构中的作用非常重要。
完成下面两步后,将自动完成登录并继续当前操作。