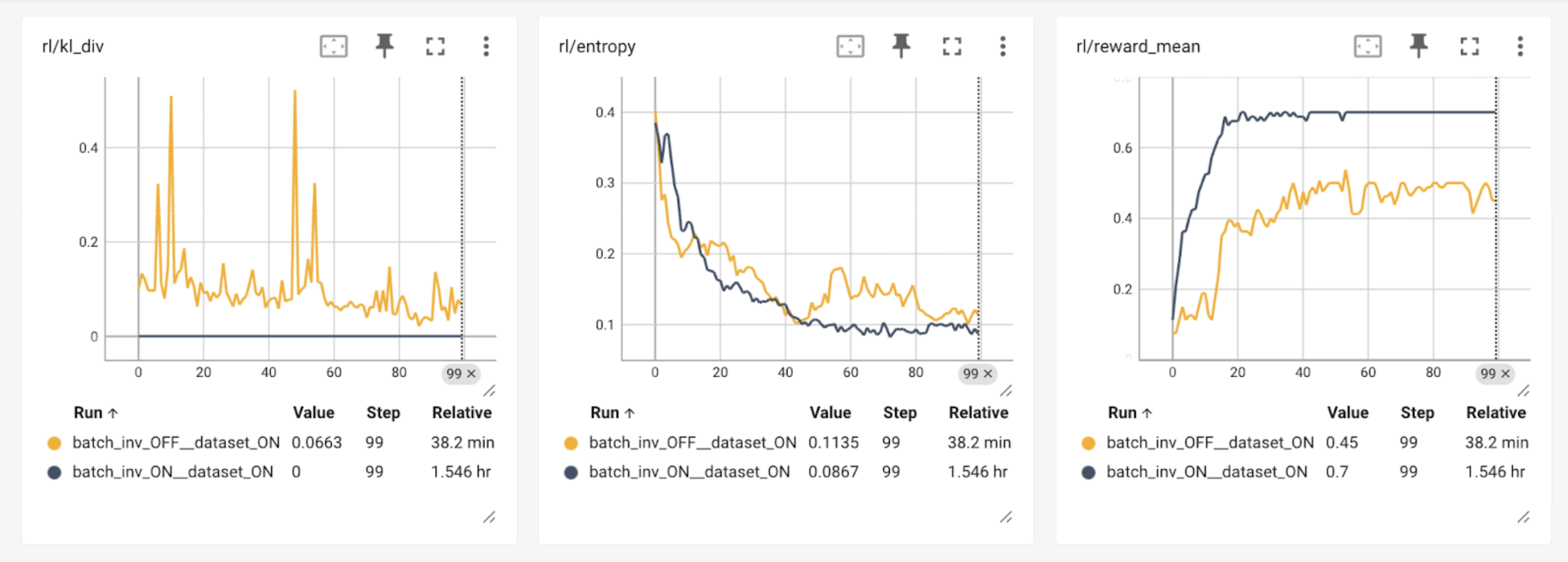
本文介绍了一个基于TorchTitan和vLLM的开源强化学习框架,强调训练和推理过程中的位一致性。研究表明,确保数值一致性可以提高模型的训练效率和奖励。未来将致力于统一模型定义、编译支持,并扩展到其他模型,以实现更广泛的位一致性。
完成下面两步后,将自动完成登录并继续当前操作。