
消除训练与推理不一致:基于vLLM和TorchTitan的位一致性在线强化学习
内容提要
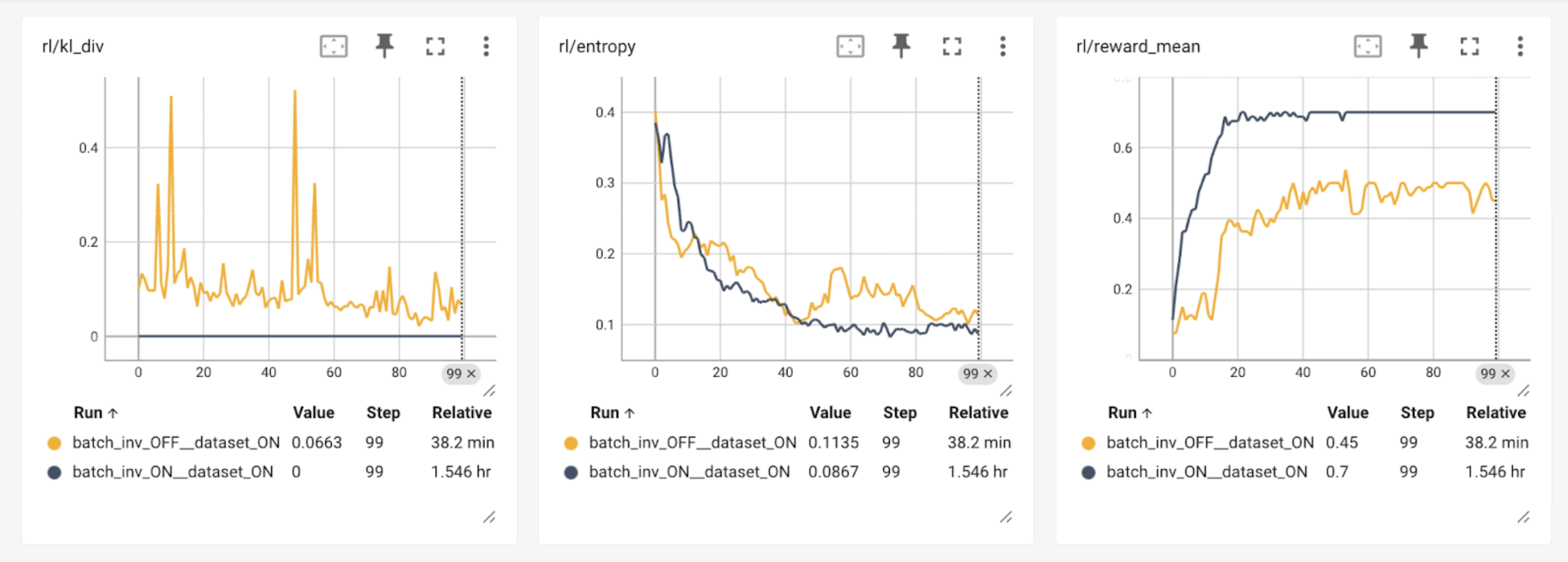
本文介绍了一个基于TorchTitan和vLLM的开源强化学习框架,强调训练和推理过程中的位一致性。研究表明,确保数值一致性可以提高模型的训练效率和奖励。未来将致力于统一模型定义、编译支持,并扩展到其他模型,以实现更广泛的位一致性。
关键要点
-
介绍了一个基于TorchTitan和vLLM的开源强化学习框架,强调位一致性的重要性。
-
研究表明,数值一致性可以提高模型的训练效率和奖励。
-
训练和推理框架通常使用不同的内核,导致数值差异和不稳定的训练行为。
-
通过审计每个内核的调用,确保训练和推理框架之间的位一致性。
-
为保持位一致性,导入了vLLM的优化操作,并编写了相应的反向传播。
-
当前的强化学习结果显示,位一致性运行比非位一致性运行慢2.4倍。
-
未来将专注于统一模型定义、编译支持和扩展到其他模型,以实现更广泛的位一致性。
-
计划将位一致性强化学习框架扩展到其他开放模型,并推广审计工具和反向实现。
延伸解读
位一致性的重要性
在强化学习中,训练和推理过程中的数值一致性至关重要。本文强调,数值不一致会导致训练行为的不稳定,影响模型的最终表现。通过确保位一致性,可以显著提高模型的训练效率和奖励,进而提升整体性能。
未来的发展方向
文章提到,未来将专注于统一模型定义和编译支持,以减少训练和推理过程中的人类错误。这一方向的推进将有助于实现更广泛的位一致性,提升模型的可维护性和可靠性。
性能与效率的权衡
当前的研究表明,位一致性强化学习的运行速度比非位一致性慢2.4倍。这提示研究者在追求数值一致性的同时,也需关注性能优化,以平衡训练效率与模型准确性之间的关系。
延伸问答
什么是基于TorchTitan和vLLM的位一致性在线强化学习框架?
这是一个开源的强化学习框架,强调训练和推理过程中的位一致性,以提高模型的训练效率和奖励。
位一致性如何影响强化学习的训练效率?
确保数值一致性可以减少训练过程中的不稳定性,从而提高训练效率和最终奖励。
当前的位一致性强化学习结果表现如何?
当前的位一致性运行比非位一致性运行慢2.4倍,但在训练效率和奖励上表现更好。
未来的研究方向是什么?
未来将专注于统一模型定义、编译支持,并扩展到其他开放模型,以实现更广泛的位一致性。
如何确保训练和推理框架之间的位一致性?
通过审计每个内核的调用,确保训练和推理框架之间的位一致性。
位一致性强化学习框架的扩展计划是什么?
计划将该框架扩展到其他开放模型,并推广审计工具和反向实现,以覆盖更广泛的操作类型。
