CVPR 2026在丹佛举行,收到16092篇投稿,华人研究者表现突出。最佳论文D4RT实现动态场景的高效重建,最佳学生论文ChordEdit由广东工业大学等团队完成,展现了本科生的实力。华人在计算机视觉领域的贡献持续增加。
何恺明团队推出了首个扩散语言模型ELF,采用105M参数和45B训练token,成功超越主流模型。ELF通过在连续空间中去噪生成离散token,显著提高生成速度和质量,展示了小规模模型的高效输出,降低了训练成本,未来有望推动AI生成速度提升。
何恺明团队推出了新的扩散语言模型ELF,该模型采用连续的embedding空间进行文本生成,显著降低了生成困惑度。ELF在训练和采样效率上表现优异,仅用105M参数和45B训练token,生成质量超过主流模型。该模型首次实现了连续与离散的有效结合,推动了扩散语言模型的发展。
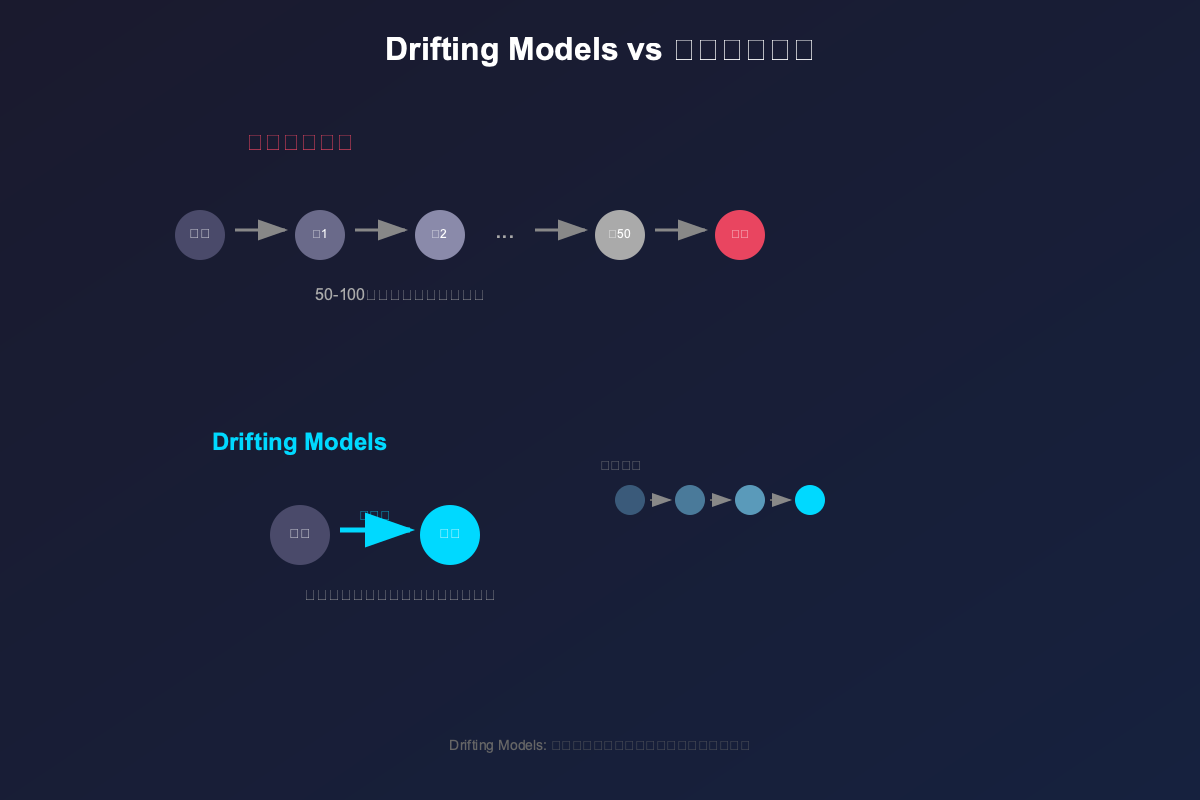
何恺明团队在arXiv发布了《Generative Modeling via Drifting》论文,提出了Drifting Models生成模型,训练时分布逐步漂移,推理时仅需一步生成,速度提升100倍,质量更佳,标志着生成模型领域的重要转折,期待广泛应用。
何恺明团队的GeoPT提出了一种新预训练范式,通过合成动力学将静态几何转化为动态空间,使模型能够在无标签数据上学习物理规律。该方法节省了20-60%的物理仿真数据,提高了训练效率和适应性,为物理仿真提供了新思路。
邓明扬与何恺明团队提出的新生成模型“漂移模型”将生成过程从推理阶段转移至训练阶段,实现单步生成。该模型通过“漂移场”机制对齐先验与真实数据分布,消除对抗训练的不稳定性,提升生成质量。在ImageNet基准测试中,漂移模型表现优异,刷新了单步生成纪录。
何恺明团队提出的Pixel Mean Flow(pMF)方法简化了扩散模型,直接在像素空间生成图像,省去了多步采样和潜空间。pMF在ImageNet上取得最佳FID成绩,验证了单步生成的可行性,推动了生成建模的进步。
抱歉,文本内容过于简短,无法有效总结。请提供更详细的文章内容。
何恺明团队推出了改进版单步生成模型iMF,解决了训练的稳定性和效率问题。在ImageNet测试中,iMF表现优异,FID成绩为1.72,超越多步扩散模型,证明其性能可与之媲美。
华尔街对谷歌TPU的关注引发学术界质疑,认为Meta等公司早已在使用TPU。谷歌与Meta的TPU交易被视为对抗英伟达的策略,但分析认为谷歌的目的不仅是盈利,更是通过合作确保芯片供应。
NeurIPS 2025最佳论文和时间检验奖揭晓,阿里Qwen门控注意力获最佳论文,何恺明的Faster R-CNN获时间检验奖。今年共七篇论文,涉及扩散模型和自监督学习等领域的突破。
何恺明团队的新论文提出扩散模型应聚焦于去噪,直接预测干净图像而非噪声。新架构JiT(Just image Transformers)设计简化,避免复杂组件,实验表明其在高维空间中表现优越,生成质量高。
抱歉,您提供的文本内容过于简短,无法进行有效总结。请提供更详细的文章内容。
何恺明在MIT新招募了本科生胡珂雅和博士后李宗宜。胡珂雅专注于AI与脑科学结合,已发表多篇高水平论文;李宗宜是傅里叶神经算子的发明者,研究物理方程的神经网络。他们将为何恺明的“AI for Science”方向贡献力量。
LSTM之父Schmidhuber质疑何恺明是残差学习的奠基人,指出早在1991年,Hochreiter已提出循环残差连接以解决梯度消失问题。他认为ResNet等深度学习成果应归功于早期研究,争论已持续多年。
MIT终身教授何恺明近期加盟谷歌DeepMind,担任兼职杰出科学家。他在计算机视觉领域有重要贡献,提出了ResNet等模型,并与谷歌合作推动生成模型研究。
机器之心数据服务现已上线,提供高效稳定的数据获取,简化数据爬取流程。
机器之心数据服务现已上线,提供高效稳定的数据获取服务,帮助用户轻松获取所需数据。
何恺明的新论文提出了一种名为Dispersive Loss的正则化方法,旨在提升扩散模型的生成效果。该方法无需预训练和数据增强,通过正则化中间表示来增强特征分散性,简化实现并提高生成质量。实验结果显示,Dispersive Loss在多种模型上显著改善生成效果,具有广泛的应用潜力。
完成下面两步后,将自动完成登录并继续当前操作。