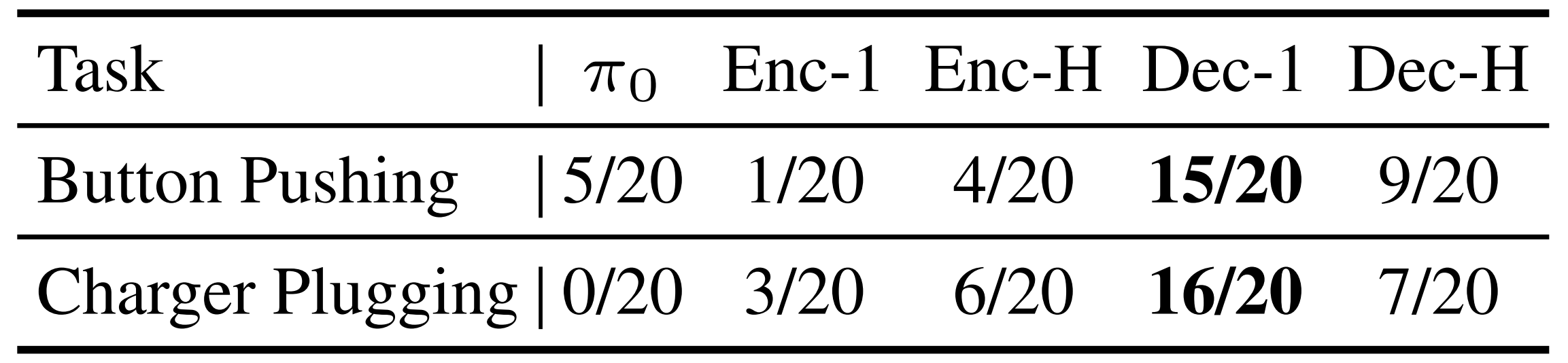
本文探讨了将关节力矩信号融入视觉-语言-动作(VLA)模型的设计,以提升机器人在物理交互中的表现。研究表明,将即时和历史力矩信息编码为单一解码器token能取得最佳效果,结合动作和力矩的预测任务可进一步增强模型性能。实验验证了该方法在高接触和常规任务中的有效性与泛化能力。
完成下面两步后,将自动完成登录并继续当前操作。