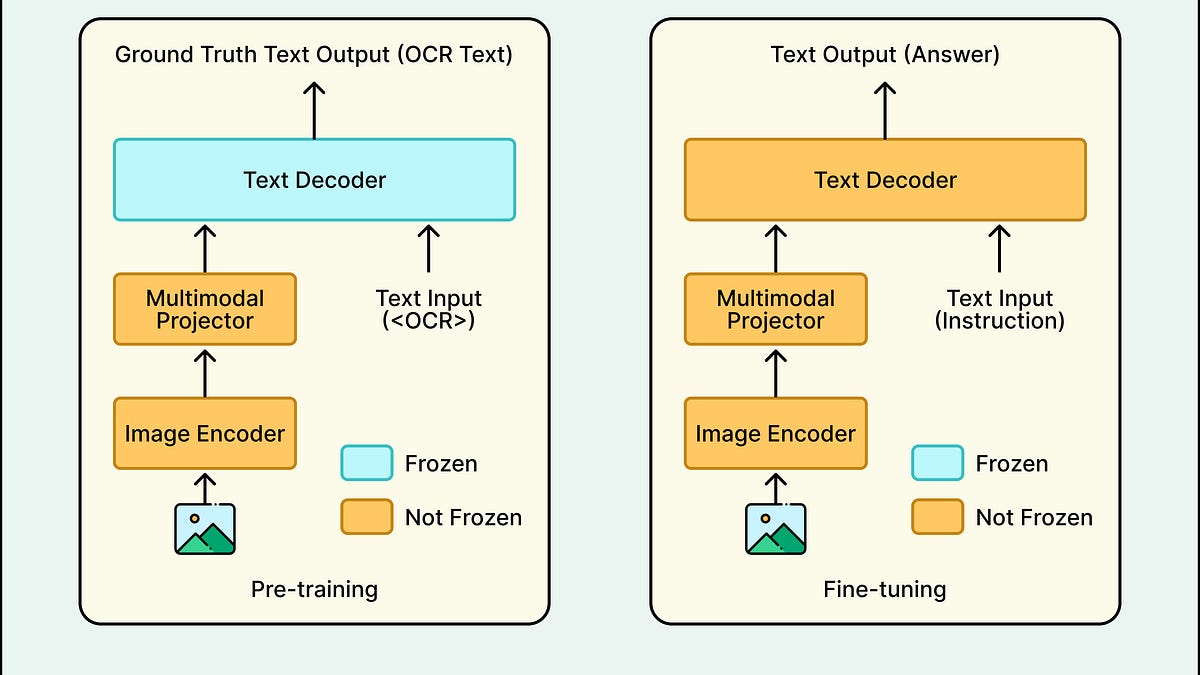
Grab团队开发了一种轻量级视觉大语言模型(Vision LLM),旨在提升东南亚语言的文档处理能力。通过合成数据和自动标注框架Documint,优化了OCR和关键信息提取的准确性,最终模型在准确性和延迟方面表现优异,展示了专用模型在文档处理中的潜力。
该研究探讨了群体枪击事件中关键信息提取的不足,并提出利用命名实体识别技术获取知识的数据集。研究表明,GPT-4o模型在提取关键实体方面表现最佳,对法律和调查工作具有重要影响。
本文介绍了多个先进的视觉语言模型(VLM)及其在图形用户界面(GUI)导航中的应用。通过构建OmniParser和CogAgent等模型,研究在文本解析、关键信息提取和表格识别等任务上取得了显著进展。此外,提出了GUICourse数据集以提升VLM的OCR和定位能力,展示了小型代理在GUI任务中的优越性能,并探讨了多模态模型在自动化计算机任务中的潜力。
完成下面两步后,将自动完成登录并继续当前操作。