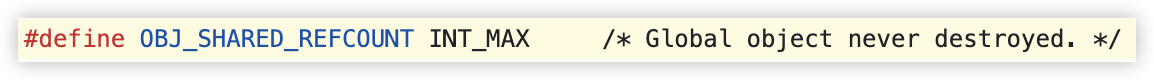文章介绍了如何在Rust中优化CEL(通用表达式语言)的性能,使其接近原生代码速度,解决了变量物化、堆分配和哈希查找等瓶颈。通过直接解析原生Rust类型的字段,减少了不必要的转换和内存开销。
Go语言的encoding/json/v2提案通过引入流式处理能力,显著降低了处理大型JSON数据的内存开销,提高了性能。基准测试表明,v2在编码和解码时的内存分配大幅减少。
随着新服务器数量增加,老服务器的内存开销问题愈发严重。通过共享内存和 mmap 技术,可以有效降低 XML 配置的内存占用。利用 Go 的 unsafe 包和结构体内存布局,能够实现高效的内存管理,减少内存消耗。
阿里云表格存储性价比高,已推出Rust版本SDK,支持多种表操作和索引功能。官方文档更新较慢,需参考其他SDK。提供链式调用,使用便捷,但重试策略会增加内存开销。
本研究提出了一种新的混合精度后训练量化方法——任务-电路量化(TaCQ),通过将关键任务权重保持为16位,显著提高了在2至3位量化条件下的模型性能,同时仅增加了少量内存开销。
本研究探讨了视觉自回归模型在推理过程中的高内存开销,首次形式化定义了KV缓存压缩问题,并证明在特定条件下,基于注意力架构的生成机制至少需要$(n^2 d)$的内存,揭示了实现次平方级内存使用的不可行性,为未来的内存优化提供了理论依据。
线程爆炸是指多个线程同时运行导致性能下降和内存开销增加的现象。本文讨论了消除线程爆炸的方法,以及Swift并发如何通过优先级管理和限制并发任务数量来有效避免这一问题,从而优化性能。
本研究提出SWAN优化器,通过引入预处理SGD的操作,解决了Adam优化器在大语言模型训练中的高内存开销问题。SWAN在内存占用与SGD相同的情况下,实现了与Adam相当的性能,特别是在训练LLaMa模型时,速度提升达2倍。
本文分析了Go语言在性能测试中的不足,特别是在十亿次循环和百万任务场景下,其速度和内存开销不如C和Java,主要由于Go编译器优化不足和Goroutine内存占用较高。希望Go团队能加强编译器优化,以提升性能。
Redis 的对象共享池旨在复用常用数据对象,减少内存开销。通过共享小整数(0-9999),Redis 提高了性能和效率。启动时,Redis 将常用对象存储在全局哈希表中,处理键值对时优先引用共享对象。该池适用于大量重复数据的场景,但共享对象不可修改,且在内存紧张时可能被禁用。
本研究提出多种量化方法以解决大型语言模型(LLMs)在长上下文任务中的内存开销问题。通过引入KV缓存的压缩技术,如CSKV和KIVI,实验表明可将内存使用降低80%,并实现高达95%的压缩率,同时保持模型性能和准确性。这些方法显著提高了推理效率和批处理能力。
本研究提出了一种名为MeZO的零阶优化方法,旨在替代反向传播法进行大规模语言模型的微调,显著降低内存开销。实验结果表明,MeZO能够在单个A100 GPU上训练数十亿参数的模型,其性能与反向传播相当。此外,结合稀疏性和量化技术,MeZO在内存受限环境中表现出色,提升了模型的训练效率和准确性。
PySpark DataFrame是Apache Spark生态系统的重要组成部分,提供了一种强大且绿色的方式来大规模处理结构化信息。然而,它也存在内存开销、学习曲线、表达能力有限、序列化开销、调试挑战和设置的复杂性等缺点。
本文介绍了一种自适应图采样方法GRAPES,解决了图神经网络内存开销过大的问题。在多个小规模和大规模图数据集上评估了GRAPES方法,并展示了其在准确性和可扩展性方面的有效性。
Node.js进行了性能改进,提升了可写和可读流的创建与销毁效率约15%,减少了内存开销。可读流的异步迭代器消费效率提高了约140%,而pipeTo的消费效率提高了约60%。同时,重构了importModuleDynamically API,解决了内存泄漏和使用后释放的问题,帮助用户顺利升级。
原型模式是Go语言中的创建型设计模式,通过复制现有对象来创建新对象,避免依赖具体类结构。适用于对象初始化成本高、需要独立副本或复杂结构复制的场景。优点包括减少创建时间和支持深浅拷贝,但可能增加内存开销。
完成下面两步后,将自动完成登录并继续当前操作。