
OLAP – 第三阶段压缩
Kimserey Lam’s website, Software Development blog posts, videos and tutorials
·
OLAP – 第一阶段向量与数据块
Kimserey Lam’s website, Software Development blog posts, videos and tutorials
·

汉斯-尤尔根·肖宁:PostgreSQL存储:存储选项比较
Planet PostgreSQL
·

Oracle 23ai中的内存顾问
DEV Community
·

DuckDB与ClickHouse Local:分析工作负载的比较分析
DEV Community
·
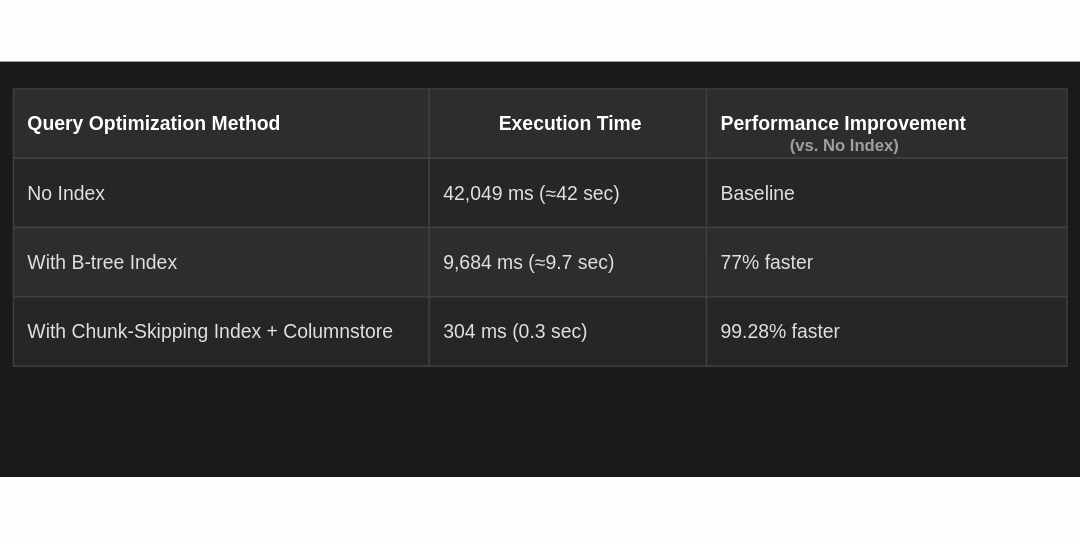
在PostgreSQL中处理数十亿行数据
Timescale Blog
·

