
在PostgreSQL中处理数十亿行数据
内容提要
在PostgreSQL中处理数十亿行数据时,使用Timescale的列存储和跳过索引功能可以显著减少表大小并提升查询速度。启用压缩后,表大小减少约95%,查询性能显著提高。TimescaleDB有效管理时间序列数据,提升存储效率和查询速度。
关键要点
-
在PostgreSQL中处理数十亿行数据时,使用Timescale的列存储和跳过索引功能可以显著减少表大小并提升查询速度。
-
启用压缩后,表大小减少约95%,查询性能显著提高。
-
TimescaleDB有效管理时间序列数据,提升存储效率和查询速度。
-
使用Timescale Cloud可以高效处理时间序列数据,提供自动扩展和高可用性。
-
创建未压缩的PostgreSQL表并插入十亿行数据后,表大小为101 GB,查询性能较差。
-
压缩后的超表在插入十亿行数据后,表大小仅为5.5 GB,查询性能显著提升。
-
压缩表的查询速度比未压缩表快,查询1的执行时间减少47.37%,查询2减少23%,查询3减少98.83%。
-
Timescale的跳过索引功能通过使用元数据动态排除不相关的分区,从而加速查询性能。
-
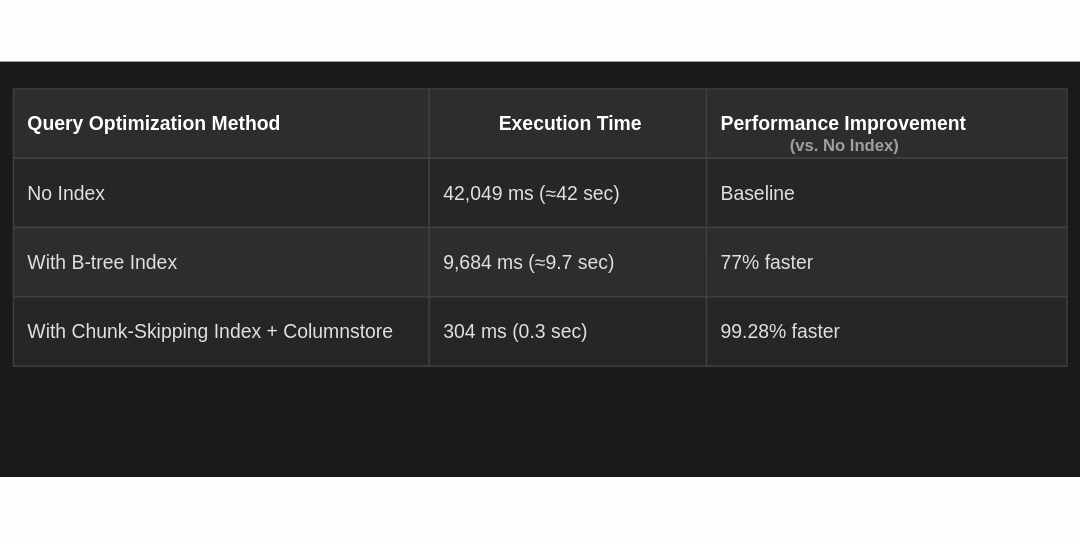
创建产品订单表并将其转换为超表后,初始查询时间为42秒,创建索引后减少到9.7秒。
-
启用跳过索引和列存储后,查询时间进一步减少到304毫秒,性能提升99.28%。
-
使用TimescaleDB的超表、列存储和跳过索引功能可以显著提升PostgreSQL性能,适合处理大规模时间序列数据。
延伸解读
压缩与查询性能的关系
启用压缩后,TimescaleDB的表大小减少约95%,这不仅节省了存储空间,还显著提升了查询性能。例如,压缩后的表在执行某些查询时,速度提升可达98.83%。因此,对于处理大规模数据的应用,压缩功能是提升性能的关键因素。
跳过索引的优势
Timescale的跳过索引功能通过动态排除不相关的分区,优化了查询性能。这意味着在处理复杂查询时,系统能够更快地定位相关数据,减少不必要的计算和I/O操作,尤其适合时间序列数据的查询场景。
使用Timescale Cloud的好处
Timescale Cloud提供了自动扩展和高可用性,简化了大规模时间序列数据的管理。开发者可以专注于数据分析,而无需担心基础设施的维护,这对于需要快速响应和高效处理数据的企业尤为重要。
延伸问答
如何在PostgreSQL中处理数十亿行数据?
可以使用Timescale的列存储和跳过索引功能来显著减少表大小并提升查询速度。
启用压缩后,PostgreSQL表的大小变化如何?
启用压缩后,表大小减少约95%。
TimescaleDB的跳过索引功能有什么优势?
跳过索引通过使用元数据动态排除不相关的分区,从而加速查询性能。
使用TimescaleDB进行时间序列数据管理的好处是什么?
TimescaleDB有效管理时间序列数据,提升存储效率和查询速度。
压缩表的查询性能与未压缩表相比如何?
压缩表的查询速度显著提高,查询1的执行时间减少47.37%,查询2减少23%,查询3减少98.83%。
如何在TimescaleDB中创建超表?
可以使用SELECT create_hypertable命令将普通表转换为超表,并设置时间分区。
