
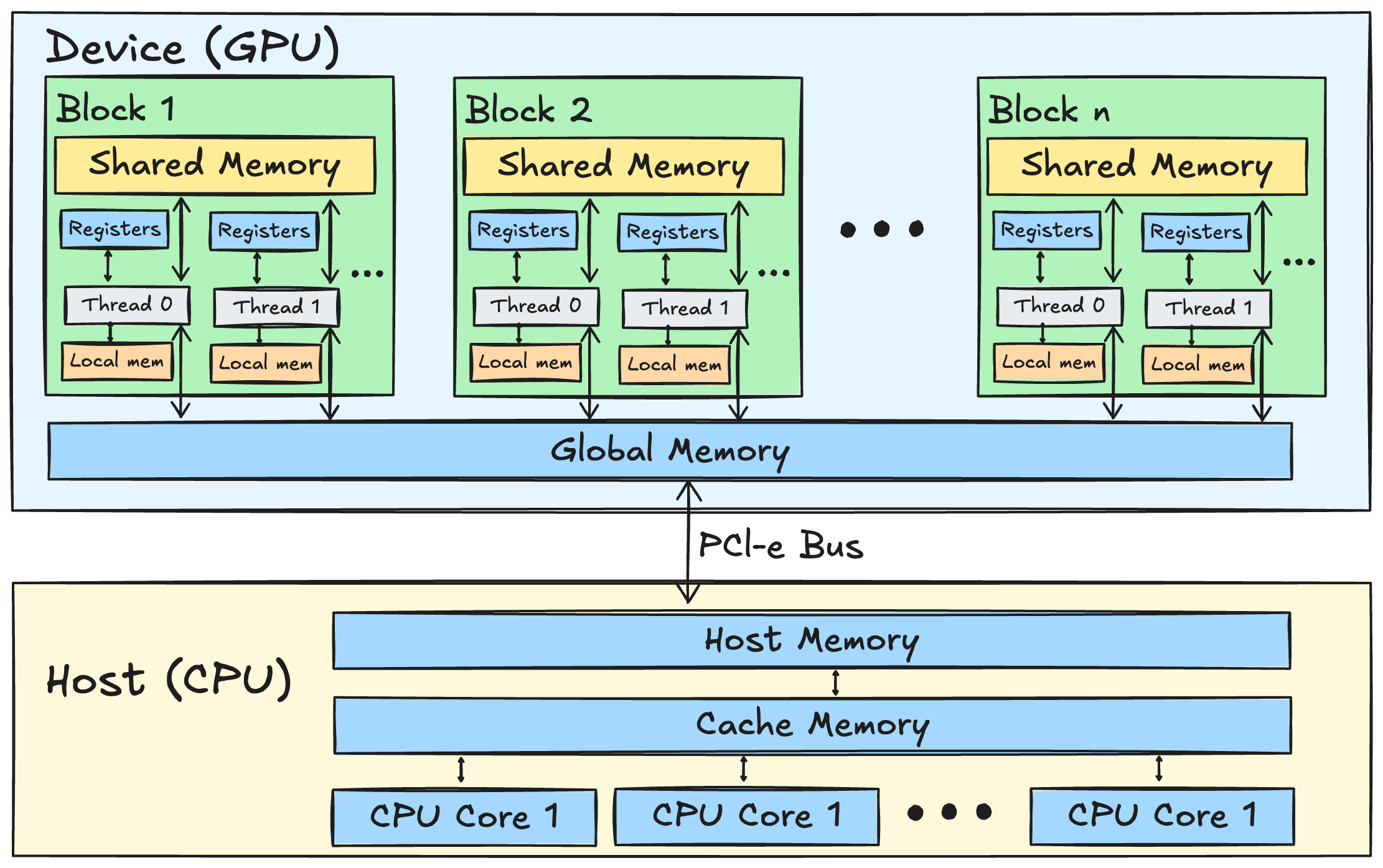
在TileLang中实现Flash Attention(比FA-2快1.3倍):第一部分
Nathan Chen
·

从零开始在Rust中实现MNIST数据集的神经网络
DEV Community
·

🚀 使用NumPy从零开始构建神经网络 🤖
DEV Community
·

从零开始解锁神经网络的力量!
DEV Community
·
