
在TileLang中实现Flash Attention(比FA-2快1.3倍):第一部分
内容提要
本文介绍了在TileLang中实现Flash Attention的前向传播,强调其内核设计、内存分配和计算过程。TileLang的性能比FlashAttention-2快1.3倍,达到630 TFLOPS/s,主要通过优化内存访问和计算并行性来提升性能。
关键要点
-
本文介绍了在TileLang中实现Flash Attention的前向传播,重点关注内核设计和计算过程。
-
TileLang的性能比FlashAttention-2快1.3倍,达到630 TFLOPS/s,主要通过优化内存访问和计算并行性来提升性能。
-
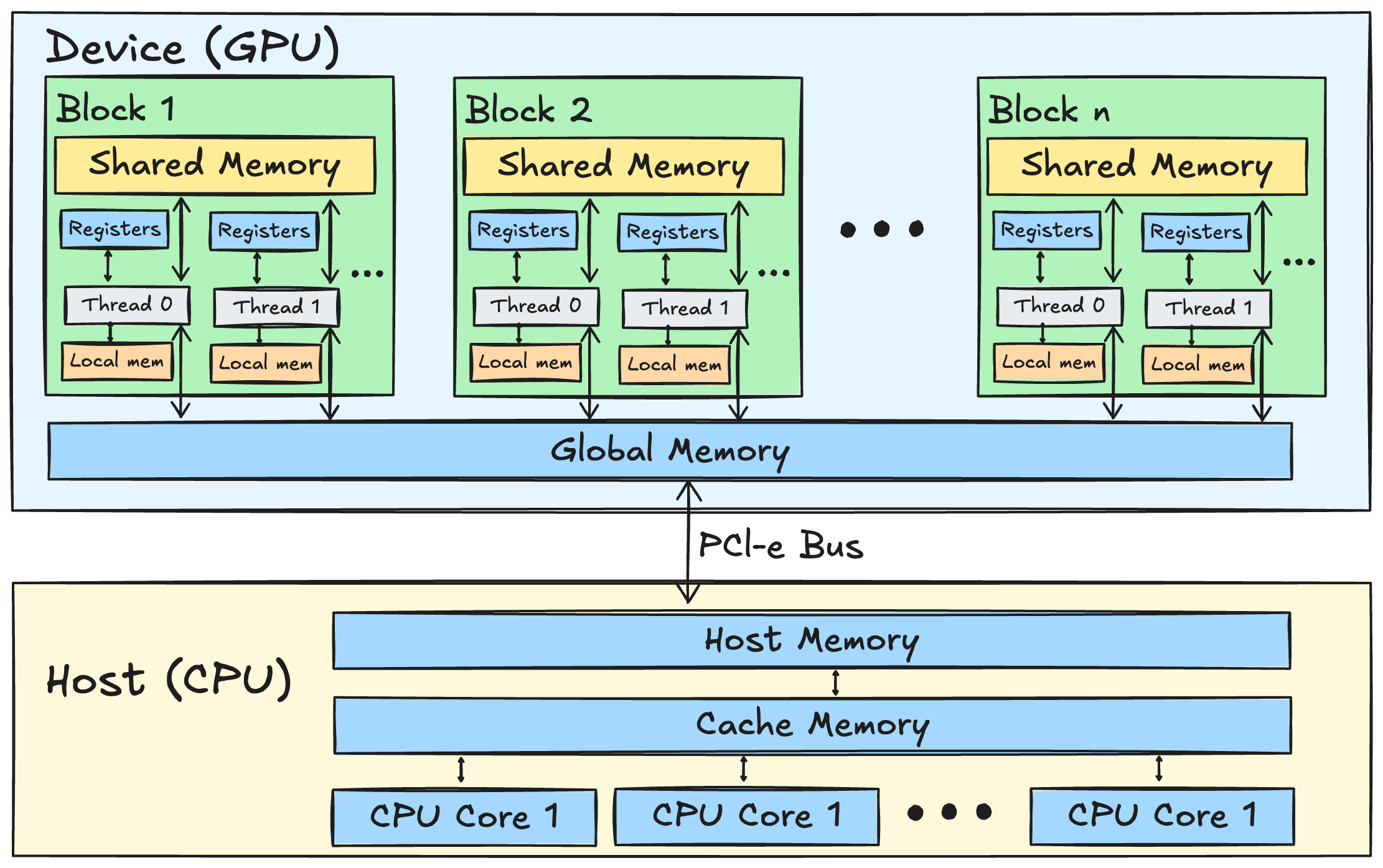
TileLang使用高效的内存分配策略,将数据从高延迟的HBM转移到快速的SRAM中,以提高计算速度。
-
内核设计采用了GPU的层次结构,利用共享内存和寄存器来减少延迟,确保计算单元的高效利用。
-
通过软件流水线技术,TileLang能够隐藏内存访问的延迟,从而提高整体性能。
-
TileLang的实现使用了bfloat16和float混合精度,以最大化算术吞吐量,确保与硬件指令的最佳匹配。
延伸解读
TileLang的内存优化策略
TileLang通过高效的内存分配策略,将数据从高延迟的HBM转移到快速的SRAM中,显著提高了计算速度。这种内存优化不仅减少了数据传输的延迟,还提升了整体性能,尤其在处理大规模数据时,能够有效降低瓶颈。
GPU架构与内核设计的关系
TileLang的内核设计充分利用了GPU的层次结构,采用共享内存和寄存器来减少延迟。这种设计使得计算单元能够高效利用,尤其是在执行复杂的矩阵运算时,能够实现更高的吞吐量和更低的延迟。
性能提升的实际意义
TileLang的实现比FlashAttention-2快1.3倍,达到630 TFLOPS/s,这一性能提升对于需要实时处理的应用场景(如自然语言处理和计算机视觉)具有重要意义。开发者在选择框架时,应考虑这种性能差异对应用效率的影响。
延伸问答
TileLang的Flash Attention实现有什么优势?
TileLang的Flash Attention实现比FlashAttention-2快1.3倍,达到630 TFLOPS/s,主要通过优化内存访问和计算并行性来提升性能。
TileLang如何优化内存访问?
TileLang使用高效的内存分配策略,将数据从高延迟的HBM转移到快速的SRAM中,以提高计算速度。
TileLang的内核设计是怎样的?
TileLang的内核设计采用了GPU的层次结构,利用共享内存和寄存器来减少延迟,确保计算单元的高效利用。
TileLang如何提高计算吞吐量?
TileLang通过使用bfloat16和float混合精度,以最大化算术吞吐量,确保与硬件指令的最佳匹配。
TileLang的实现中使用了哪些技术来隐藏内存延迟?
TileLang通过软件流水线技术,能够隐藏内存访问的延迟,从而提高整体性能。
TileLang的性能测试结果如何?
TileLang在性能测试中显示出比Flash Attention 2更快的速度,具体表现为在相同问题规模下的更低延迟和更高TFLOPS。
