DeepSeek发布的Tile Kernels通过TileLang优化GPU性能,打破了CUDA的垄断,推动AI工程从模型设计转向系统能力。TileLang简化了GPU开发,支持跨硬件执行,提升了效率。然而,技术进步导致能力差距扩大,顶级团队获得更高效率,而大多数团队难以跟上。这一变化将重塑AI基础设施的竞争格局。
第八届CCF开源创新大赛的开源GPU创新生态赛正在进行,旨在推动国产算力创新,吸引全球开发者参与。TileLang作为技术亮点,提供高效的GPU开发工具,降低开发门槛,促进国产GPU生态发展。赛事报名时间为2025年9月15日至12月10日,欢迎开发者参与。
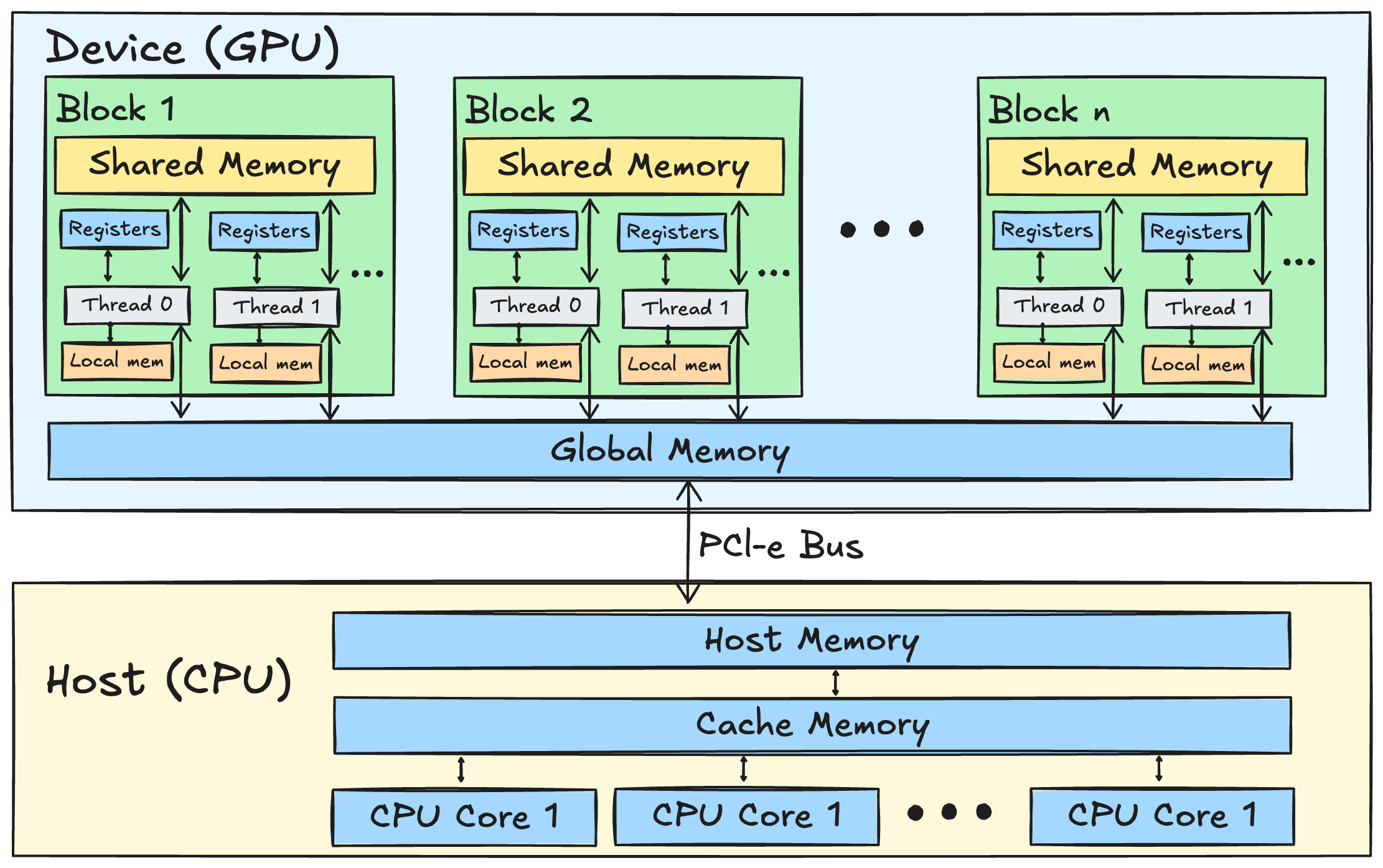
7月5日,Meet AI Compiler技术沙龙在北京举行,专家介绍了TileLang算子编程语言的设计理念与优势。TileLang旨在提升AI内核编程效率,通过解耦调度空间与数据流,简化用户操作。评估结果显示,TileLang在多个关键内核上表现优异,展现了其在现代AI系统开发中的性能与灵活性。
本文介绍了在TileLang中实现Flash Attention的前向传播,强调其内核设计、内存分配和计算过程。TileLang的性能比FlashAttention-2快1.3倍,达到630 TFLOPS/s,主要通过优化内存访问和计算并行性来提升性能。
2025 Meet AI Compiler 技术沙龙将于7月5日在北京中关村举行,邀请多位专家探讨AI编译器的最佳实践与趋势,进行圆桌讨论。活动时间为13:30-17:45,预计有200人参加,现场提供茶歇。
超神经将于7月5日在北京举办第7期Meet AI Compiler技术沙龙,邀请AMD等专家探讨AI编译器的前沿实践,包括Triton编译器和TVM应用,并进行圆桌讨论。活动提供礼品与茶歇,欢迎参与。
在 AI 变革时代,AI 编译器成为连接硬件与应用的关键技术。7 月 5 日,HyperAI 超神经将在北京举办技术沙龙,邀请专家分享 AMD Triton 编译器、TileLang 和 TVM 的最佳实践与趋势,探讨跨硬件的统一编译生态。
完成下面两步后,将自动完成登录并继续当前操作。