

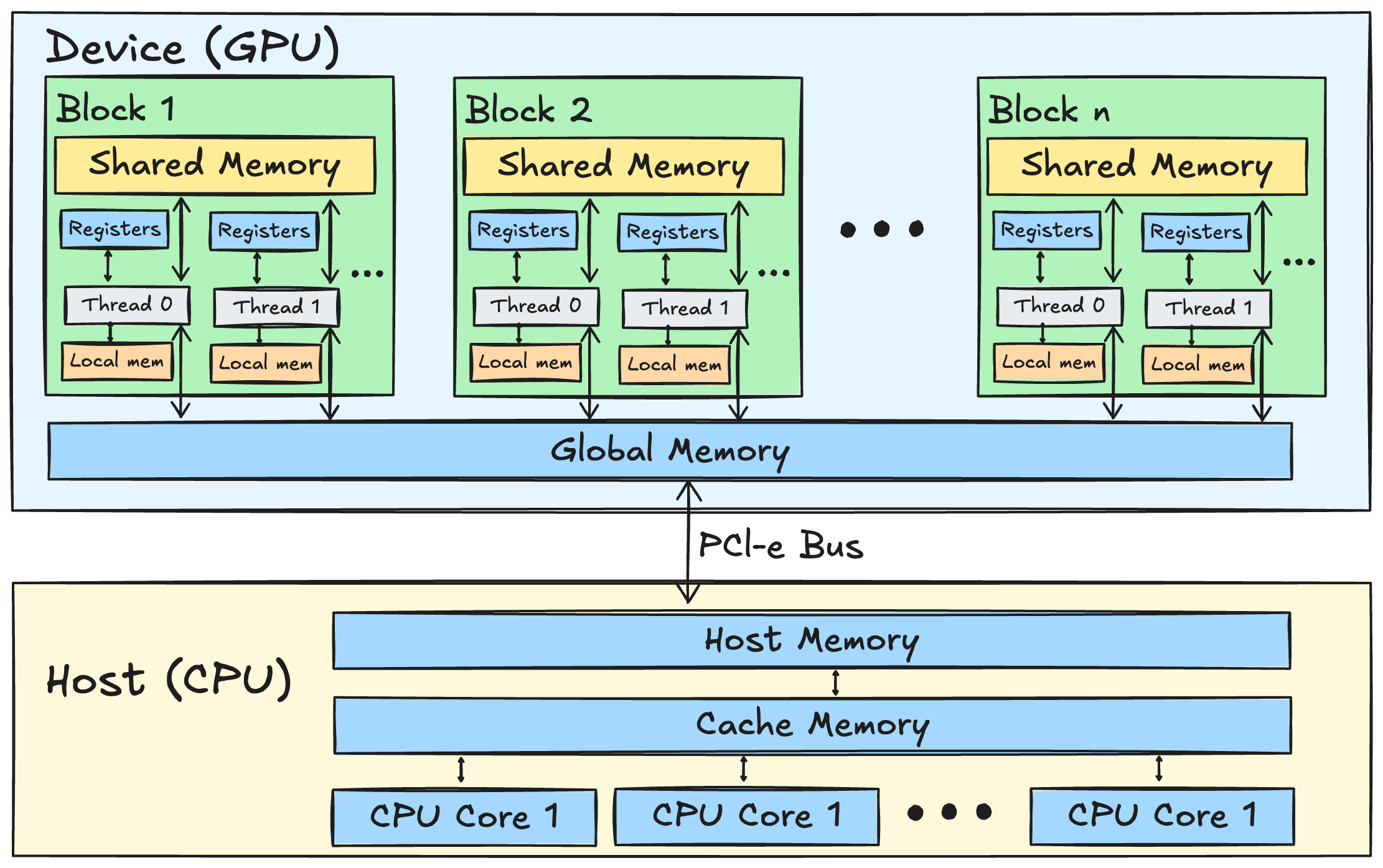
在TileLang中实现Flash Attention(比FA-2快1.3倍):第一部分
Nathan Chen
·

视觉指南揭示FlashAttention如何提高AI内存管理效率
DEV Community
·
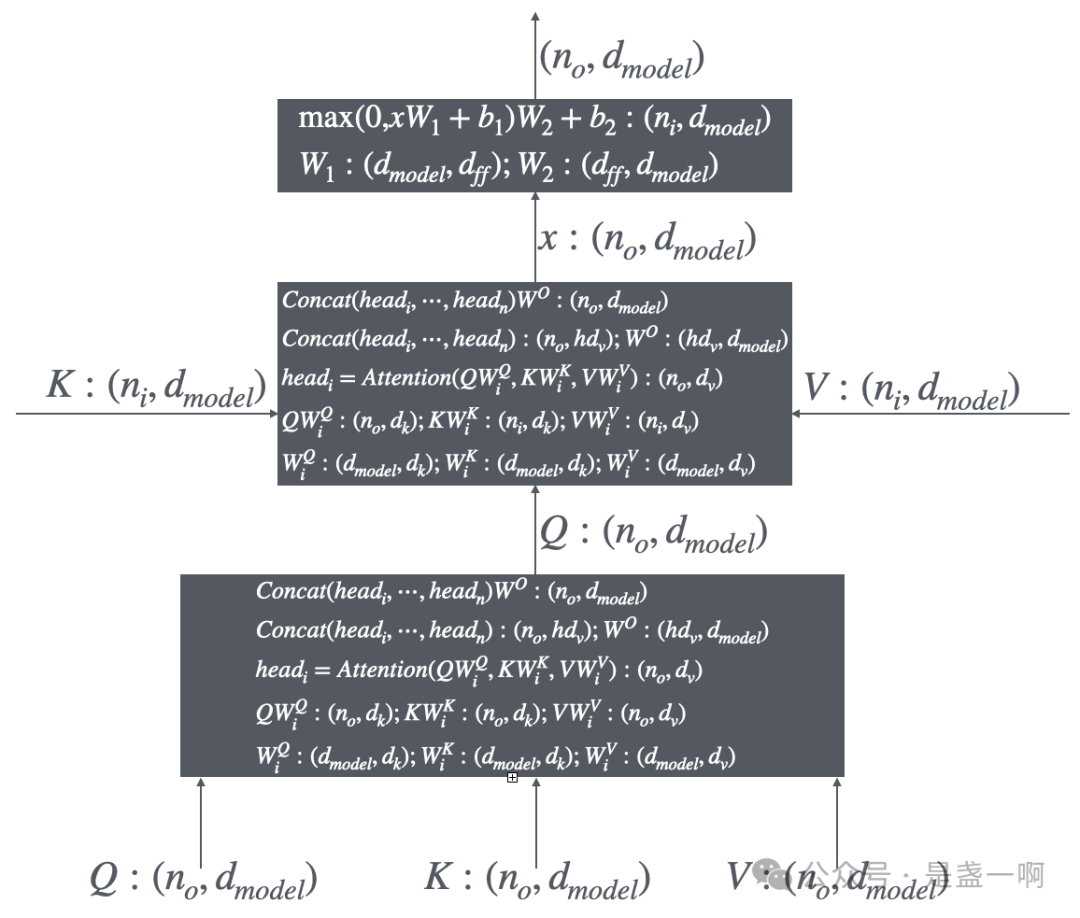

CUDA 内核融合研究案例:在 NVIDIA Hopper 架构上使用 CUTLASS 库实现 FlashAttention-2
BriefGPT - AI 论文速递
·
