星海图提出的G0.5模型将视觉语言模型与动作生成统一为单一自回归序列,通过共享权重实现推理与动作的耦合,提升机器人控制效率。该模型采用可学习的动作分词器和视觉记忆模块,优化动作生成过程,减少离散化负担,能够在零样本条件下分解任务,直接生成动作,增强对复杂场景的适应能力。
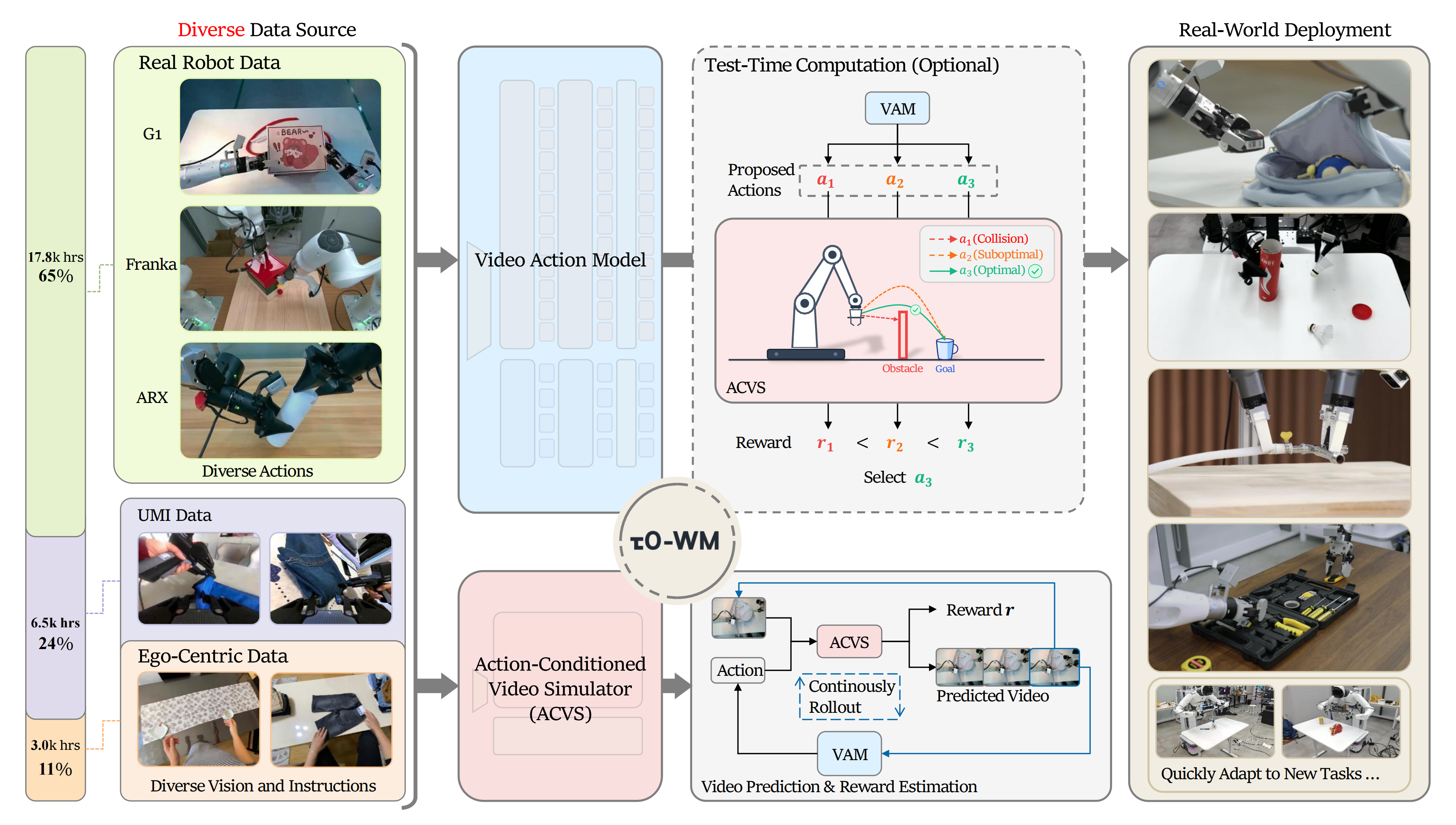
研究者提出了一种名为τ0-World Model(τ0-WM)的统一视频-动作世界模型,旨在提升机器人操作的预测能力。该模型结合视频预测、动作生成和任务评估,利用27,300小时的多样化数据进行训练。τ0-WM通过共享的预测网络,提供视频动作模型和动作条件视频模拟器两个接口,优化机器人在执行前的决策过程。
GraspVLA是一种基于十亿级合成抓取数据集的机器人抓取模型,结合视觉语言模型和动作生成机制,提升了抓取技能的泛化能力。该模型通过渐进式动作生成方法,实现了仿真到现实的迁移,展现出优异的零样本性能。
北大和人大团队在通用人形机器人动作生成领域取得突破,推出百万规模数据集MotionLib和动作生成模型Being-M0,实现复杂人类动作向多类型机器人迁移,提升跨平台适配能力。
本研究提出R-Lodge模型,解决生成舞蹈模型中表现一致性不足的问题,通过舞蹈校准技术和递归序列表示学习,显著提升舞蹈动作的一致性。
研究团队提出了一种新型多模态语言模型,能够同时处理音频和文本输入,并生成相应的动作。该模型统一了人类动作的言语和非言语语言,尤其在数据稀缺情况下展现出优异的动作生成和理解能力。
本研究提出了一种新的粗到细自回归策略学习框架(CARP),旨在提高机器人视觉运动策略学习的效率和灵活性。该框架通过多尺度表示学习和细化预测两个阶段,显著提升了动作生成的精度和流畅性,推理速度提高了10倍,并实现了竞争性的成功率。
文章介绍了OmniH2O人形机器人,通过语音指令和预训练的文本到人体动作生成扩散模型(MDM)来控制动作。MDM利用文本提示生成多样化动作,体现文本到动作的多对多映射。其目标是在特定条件下合成人体动作,支持多种输入。扩散建模采用马尔可夫噪声过程,并使用几何损失正则化生成自然连贯的动作。
本研究提出了一种轨迹感知主要流形框架,旨在恢复流形骨干并生成样本。通过内在维度正则化,该框架实现了紧凑的流形表示和少样本图像生成。实验结果表明,该方法在分类准确性和样本生成方面表现优越,尤其在复杂文本描述下的动作生成任务中。
本文介绍了基于扩散模型的人体动作生成方法,重点在于细粒度控制、语义对齐和高质量合成。研究提出的新算法GMD和LGTM显著提升了文本驱动的动作生成效果,尤其在复杂描述下表现优越。通过层次化和多阶段流程,解决了语义差异问题,实现了更准确的动作生成。
本研究提出了基于扩散模型的动作生成框架ReMoDiffuse,通过结合检索机制改善去噪过程,提升文本驱动动作生成的多样性。相关模型如MoDiff、MotionDiffuse和CrossDiff在运动合成和预测方面表现优异,能够生成复杂的人类运动,适应实时命令,展现出强大的鲁棒性和生成质量。
本研究介绍了CameraCtrl模型,通过精确控制相机姿态提升T2V模型的可控性和泛化性。结合三维相机运动和多模态变压器,能够有效生成视频。提出的协作视频扩散(CVD)框架通过跨视频同步模块提高了不同相机轨迹下视频的一致性。此外,CoMo模型在动作生成和编辑方面表现优异,VideoComposer模型实现了合成视频的条件控制。研究还提出了Direct-a-Video和COMD模型,增强了用户对对象和相机运动的控制能力。
本文探讨了基于文本描述生成3D人体动作的方法,提出了多角度注意机制和TEMOS框架,利用变压器实现高质量动作生成。实验结果表明,该方法在多个数据集上优于现有技术,能够根据文本条件生成多样化的动作序列。
本文介绍了一种基于文本描述生成多样3D人类动作的方法,提出了TEMOS框架,利用变分自编码器生成高质量动作序列。研究表明,该框架在多个基准测试中表现优越,结合语言结构和上下文推理模块,提升了动作生成的精确度和多样性。
该研究提出了多种基于扩散模型的视频和动作生成方法,包括可控运动扩散模型(COMODO)和RAVE视频编辑技术,显著提高了生成质量和多样性,适用于人机协作和视频编辑等场景。
本文提出了一种使用多角度注意机制的两阶段方法,通过生成变压器实现文本驱动的运动生成,实现了精细合成和动作生成。实验证明该方法优于现有技术。
完成下面两步后,将自动完成登录并继续当前操作。