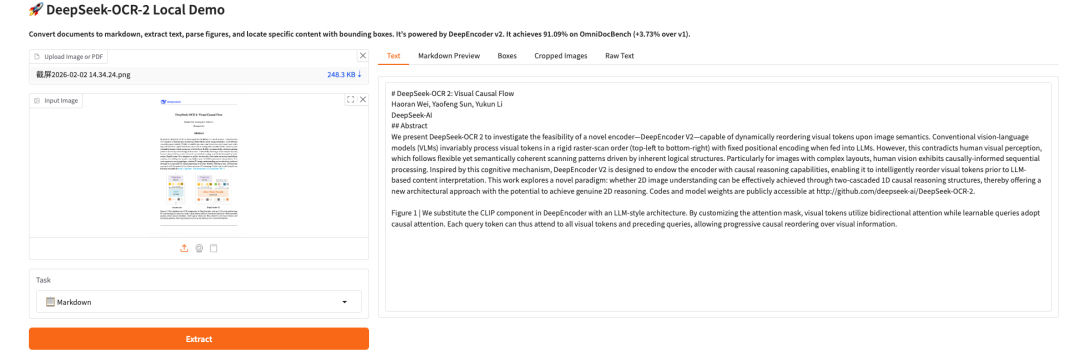
奇异摩尔首次亮相WAIC 2026
本文介绍了多个 Rust 项目,包括 yring、bon、Truce 1.0 和 BlazePilot。yring 提高了 SPSC 队列的吞吐量,bon 反思了 builder 生成器的使用场景,Truce 1.0 统一了音频插件格式,BlazePilot 展示了现代化的 Linux 文件管理器。这些项目推动了 Rust 生态的发展。
清华大学智能产业研究院的GS-Playground是一个新型多模态仿真框架,旨在推动具身人工智能的发展。该平台结合高保真视觉渲染与并行物理仿真,支持多种机器人形态的训练,提高了训练效率和真实场景迁移能力。GS-Playground通过自动化工作流简化了仿真环境构建,降低了成本,未来将开源以促进行业发展。
清华大学智能产业研究院与多家技术公司合作推出GS-Playground通用多模态仿真框架,旨在解决具身人工智能领域的核心难题。该平台实现高吞吐量并行物理仿真与高保真视觉渲染的深度融合,支持多种机器人形态的训练与部署,显著提高仿真效率与稳定性,并能快速将真实场景转化为数字资产,推动机器人技术的发展与应用。
OpenBMB推出的MiniCPM-o-4.5模型仅用9B参数实现全模态能力,强调跨模态对齐与推理效率,适合主流GPU部署,具备高性能与轻量化优势。
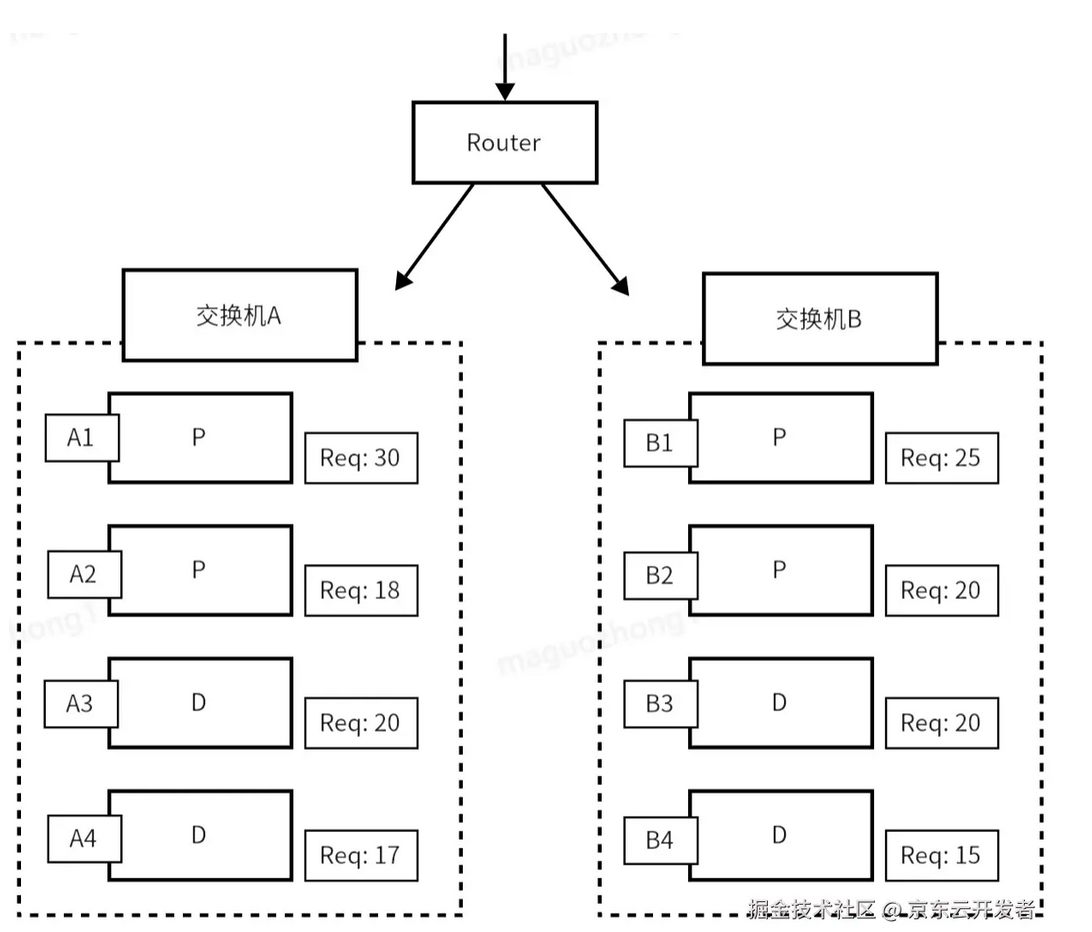
测试表明,NetServer在纯接收情况下每秒可处理1.4亿数据包,带编码协议头时每秒可处理190万个RPC请求。与StandardCodec相比,LengthFieldCodec在吞吐量和内存使用上表现更佳,滑动窗口模式提升显著。建议减少字典查找以优化性能。
京东云推出云原生AI推理框架,解决传统推理系统的稳定性、资源利用率和性能瓶颈问题。该框架通过智能流量调度、自动弹性扩缩容和故障自愈机制,提升推理效率和资源利用率,短文吞吐提升超过120%,GPU资源节省约26%。
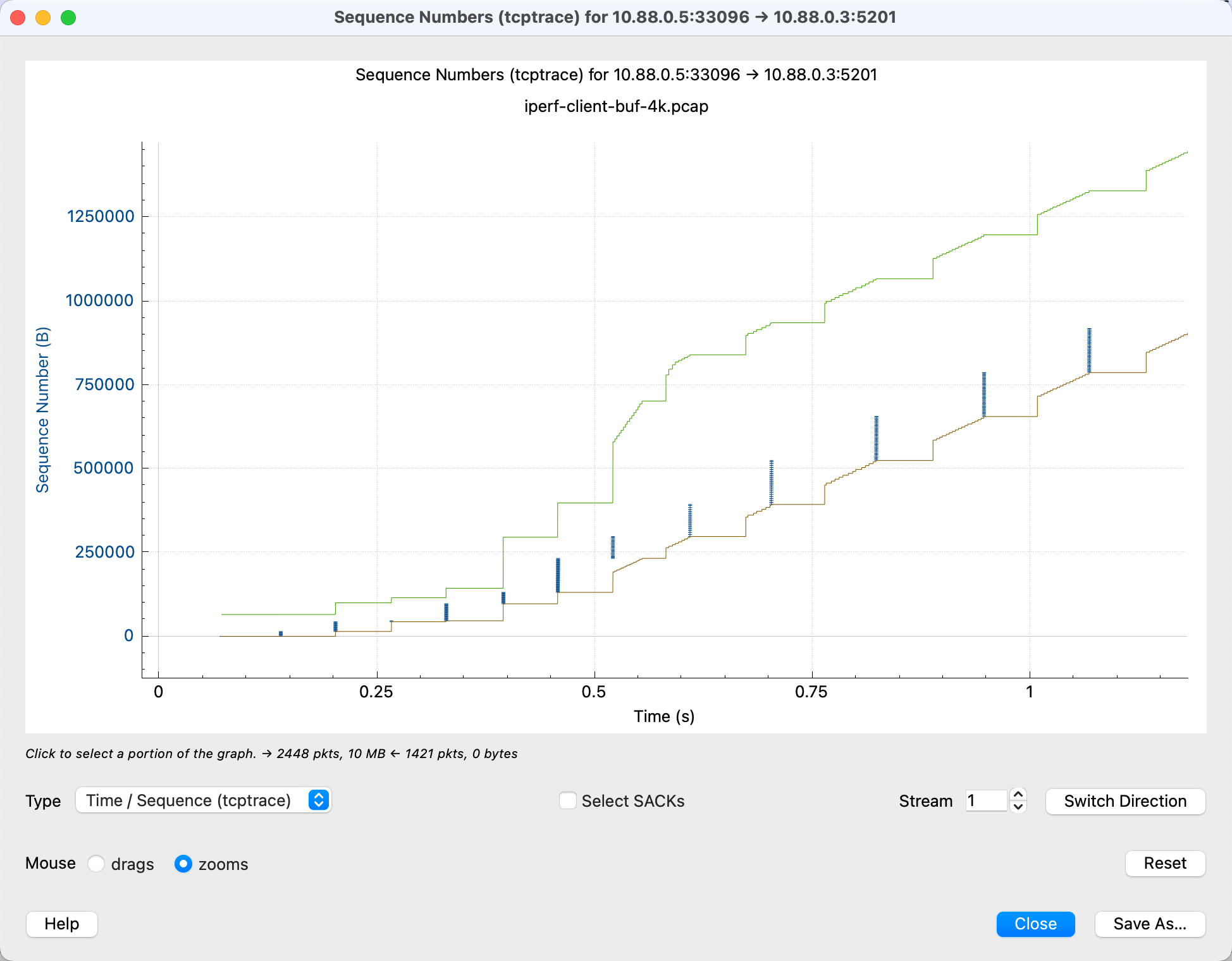
tcptrace用于分析TCP吞吐问题,图中横轴为时间,纵轴为序列号。蓝线表示发送数据,绿色线为接收窗口,棕黄线为已确认数据,红线为选择确认。通过图中距离可得出在途字节、窗口余量和RTT等信息。建议同时抓包以获取全面数据,常见问题如丢包和窗口限制可通过图形化方式分析。
分析抓包文件显示,新设备吞吐量下降主要因网卡LRO功能失效,导致数据包处理效率降低。尽管新旧设备转发速度相似,但包大小分布和ID不连续影响性能,造成部分请求超时。
rathole是一款开源的轻量级内网穿透工具,延迟与frp相近,但在高并发下表现更佳,资源占用更少。支持Windows、macOS、Linux,需公网IP,配置简单,但更新不频繁,建议无必要不折腾。
在2025大模型服务性能排行榜中,PPIO在DeepSeek-R1-0528的吞吐测试中以45.17 tokens/s排名第一,表现出色,获得行业认可,专注于优化AI基础设施。
机器之心数据服务现已上线,提供高效稳定的数据获取,简化数据爬取流程。
英伟达推出的Llama Nemotron Super v1.5开源模型专为复杂推理和智能体任务设计,吞吐量提升三倍,单卡高效运行。该模型通过神经架构搜索优化,兼顾准确性与效率,适合英语对话和编程任务。
浙大与上海AI Lab提出的邻近自回归建模(NAR)通过“下一个邻域预测”显著提升了视觉生成的效率和质量。NAR模型在多个任务中实现了13.8倍的吞吐量提升,减少了生成步骤,特别在高分辨率图像和视频生成中表现出优势。
飞桨框架3.0增强了大模型推理能力,支持多种主流大模型,优化了量化和推理性能。通过4比特量化,单机部署显著提升吞吐量,同时支持FP8和INT8量化。MLA算子优化提升了23%性能,MTP投机解码加速大批次推理,整体提供高效、经济的推理部署方案,兼容多种硬件平台。
随着大语言模型对长文本需求的增加,注意力机制的计算成本和键值缓存问题愈发明显。清华大学等团队提出了混合稀疏注意力(MoA)方法,通过不同稀疏度的注意力头,显著提升了上下文理解能力和计算效率,减少了内存需求,优化了长文本处理效果。实验结果表明,MoA在多种模型上表现优异,提高了信息检索准确率和生成吞吐量。
清华大学PACMAN实验室发布了MixQ开源系统,支持8比特和4比特混合精度推理,实现大模型的近无损量化并提升推理速度。MixQ通过量化权重和激活,利用低精度张量核心加速推理,并提取激活中的离群值以保持准确性。该系统已支持多个主流大模型,并在SC’24会议上发表。其设计通过等价变换、数据结构优化和高性能算子生成,显著提升性能。
颜水成和袁粒团队提出了新架构MoE++,通过引入“零计算量专家”提升性能和速度。MoE++允许每个Token使用不同数量的FFN专家,降低计算成本,提高复杂Token处理能力。实验表明,MoE++在相同模型大小下性能优于传统MoE,专家吞吐速度提升1.1到2.1倍。模型权重已开源,展示了不同任务中的专家负载分布差异。
本文介绍了一种新方法,通过优化大型语言模型中的键值缓存,显著降低内存使用并提高推理吞吐量。该方法可减少内存消耗高达70%,提升吞吐量2.2倍,适用于多种模型和任务。采用自适应KV缓存和SqueezeAttention等技术,保持生成质量的同时提高效率。
论文提出了一种新的CNN-ViT混合神经网络FasterViT,旨在提高计算机视觉应用中的图像吞吐能力。FasterViT结合了CNN的局部特征学习和ViT的全局建模,通过分层注意力方法优化计算成本和窗口间交互。该模型在分类、对象检测和分割等任务中表现出色,尤其在高分辨率图像处理上具有优势。
完成下面两步后,将自动完成登录并继续当前操作。