
AI推理:如何实现吞吐翻倍、时延降90%与GPU资源节省26%?
内容提要
京东云推出云原生AI推理框架,解决传统推理系统的稳定性、资源利用率和性能瓶颈问题。该框架通过智能流量调度、自动弹性扩缩容和故障自愈机制,提升推理效率和资源利用率,短文吞吐提升超过120%,GPU资源节省约26%。
关键要点
-
京东云推出云原生AI推理框架,解决传统推理系统的稳定性、资源利用率和性能瓶颈问题。
-
该框架通过智能流量调度、自动弹性扩缩容和故障自愈机制,提升推理效率和资源利用率。
-
短文吞吐提升超过120%,GPU资源节省约26%。
-
系统设计遵循解耦与组合、扩展性优先和引擎无感接入的原则。
-
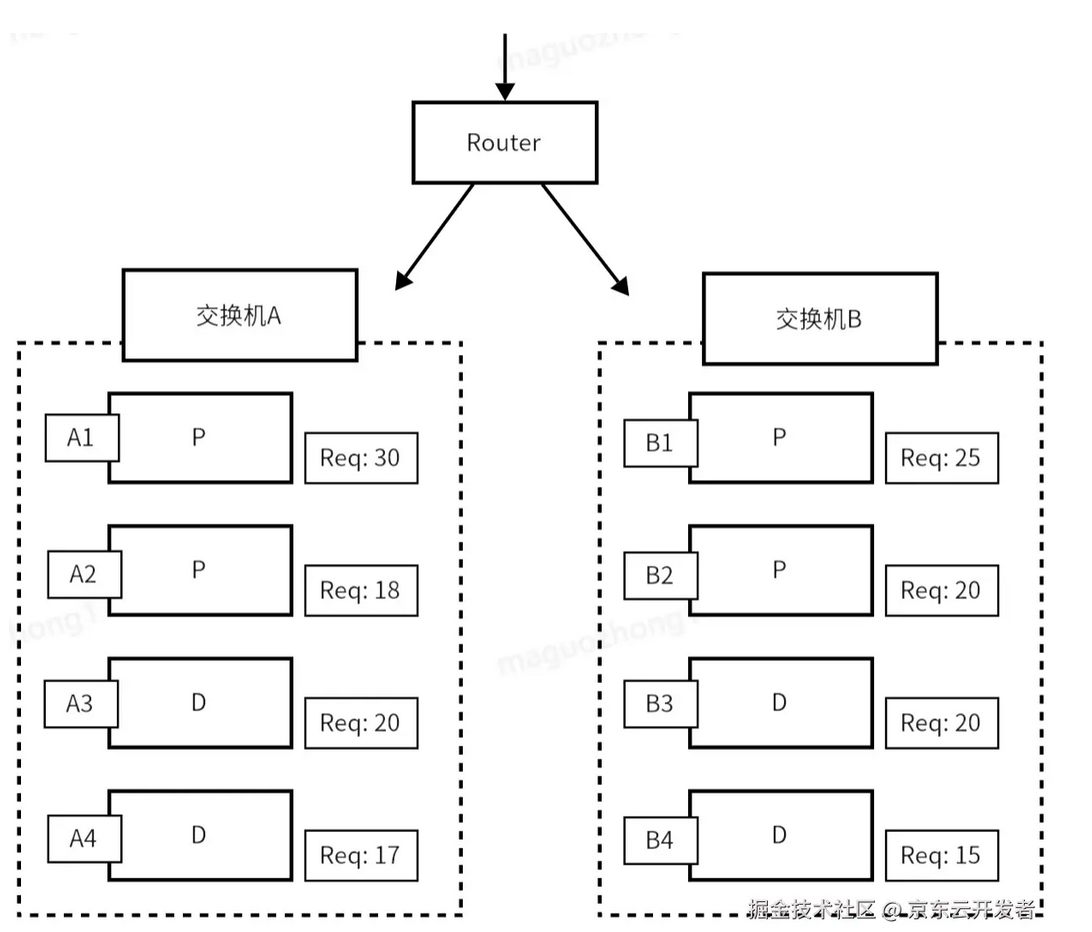
通过长短文分桶与跨集群调度,显著降低短文TTFT,提升整体吞吐。
-
实现全场景自动弹性伸缩,提升资源利用率,节省GPU卡时。
-
故障自愈机制提高了系统的稳定性和业务连续性,减少人工干预。
-
客户案例显示,云原生系统显著提升了GPU吞吐能力和用户请求响应率。
延伸解读
云原生技术的优势
京东云的云原生AI推理框架通过智能流量调度和自动弹性扩缩容,显著提升了推理系统的稳定性和资源利用率。这种技术的应用不仅能应对高并发请求,还能有效降低资源闲置,适应业务需求的波动,帮助企业在AI规模化落地中获得更高的效率。
故障自愈机制的重要性
故障自愈机制是京东云推理框架的一大亮点,它能够在容器故障时自动隔离并启动新副本,减少人工干预。这一机制不仅提高了系统的稳定性,还保障了业务的连续性,降低了因故障带来的损失,尤其在高负载情况下显得尤为重要。
资源利用率的提升
通过全场景自动弹性伸缩,京东云的框架实现了GPU资源的节省,提升了资源利用率约26%。这种优化不仅降低了运营成本,还能在流量低谷期有效避免资源浪费,为企业提供了更灵活的资源管理方案。
延伸问答
京东云的AI推理框架解决了哪些传统推理系统的问题?
该框架解决了稳定性不足、资源利用率低、推理性能瓶颈和定制成本高等问题。
京东云的AI推理框架如何提升推理效率?
通过智能流量调度、自动弹性扩缩容和故障自愈机制,提升推理效率和资源利用率。
短文和长文的吞吐量提升了多少?
短文吞吐提升超过120%,长文吞吐提升约30%。
该框架在GPU资源利用方面有什么成效?
框架实现了GPU资源节省约26%。
京东云的AI推理框架如何实现故障自愈?
通过实时健康监测,快速感知故障容器并进行隔离,启动新副本实现故障自愈。
云原生AI推理框架的设计原则是什么?
设计原则包括解耦与组合、扩展性优先和引擎无感接入。
