
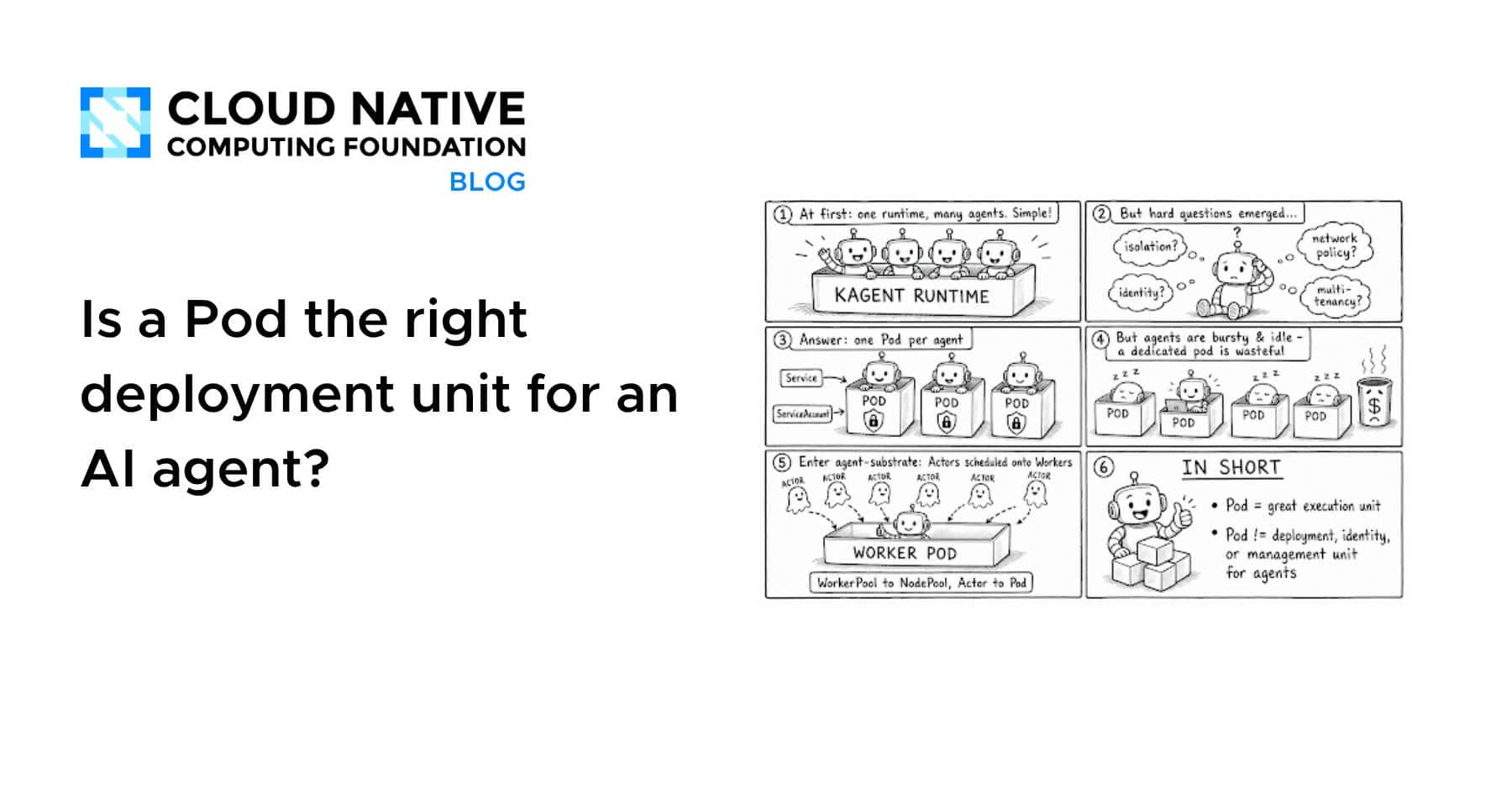
Pod是否是AI代理的合适部署单元?
Cloud Native Computing Foundation
·
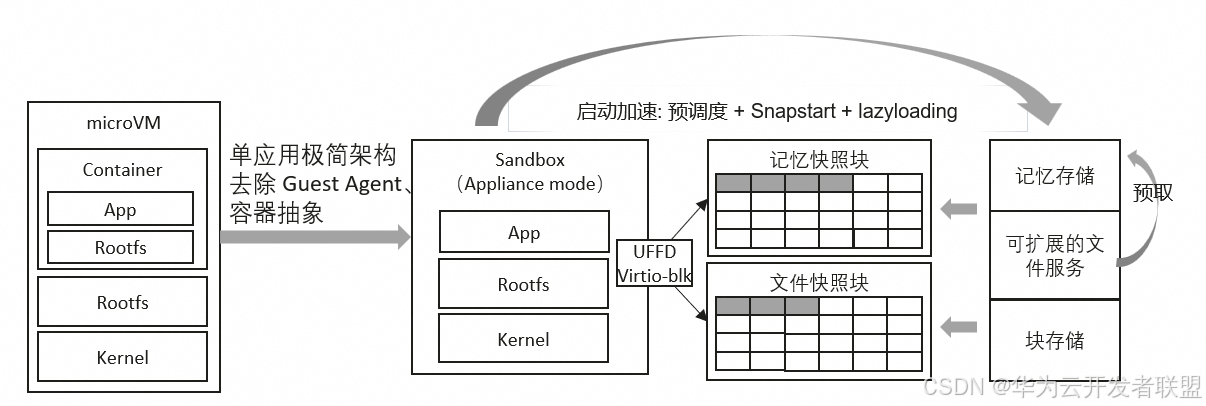

Network Firewall 部署小指南 (五) 使用辅助VPC端点简化NFW部署及运维管理
亚马逊AWS官方博客
·
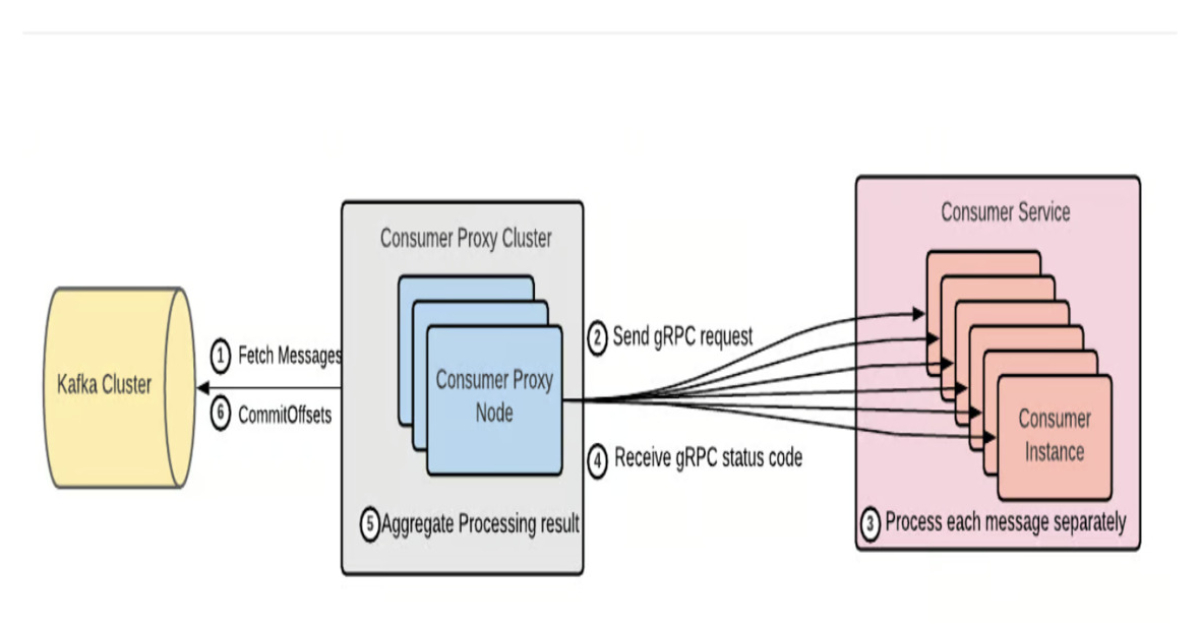
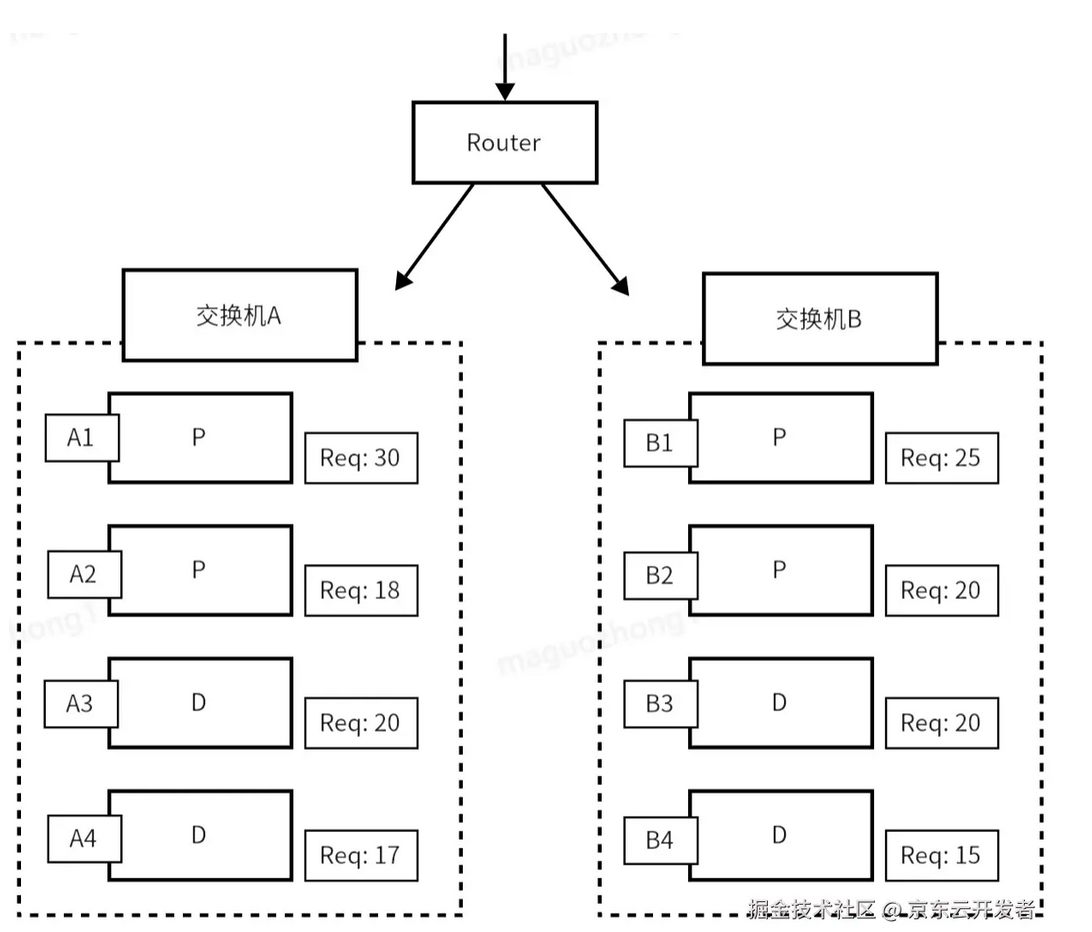
AI推理:如何实现吞吐翻倍、时延降90%与GPU资源节省26%?
京东科技开发者
·

一种轻量级进程间服务隔离方法实践
京东科技开发者
·


数据库性能优化终极指南
Redis Blog
·
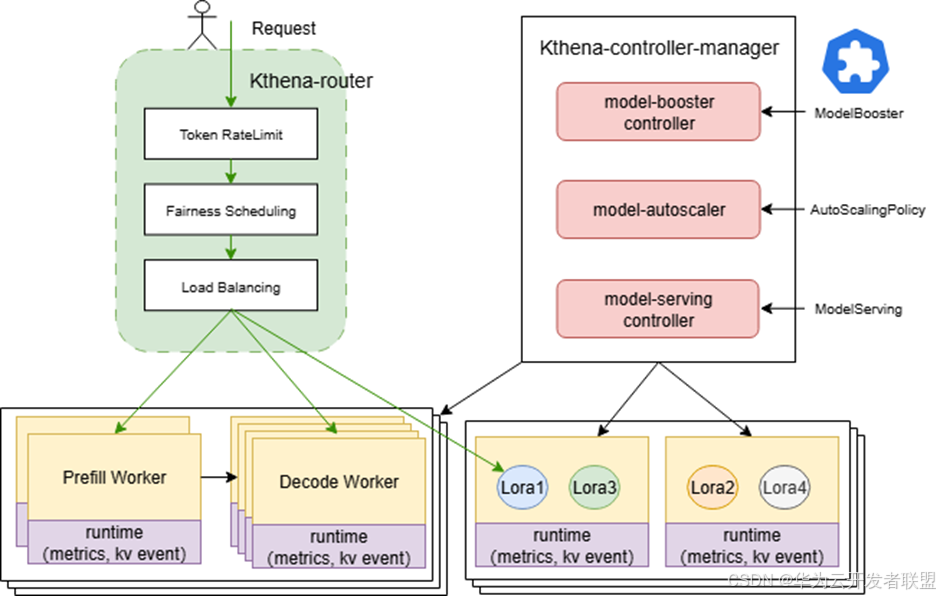
Volcano 社区发布 Kthena 子项目 | 重新定义大模型智能推理
华为云官方博客
·



基于 HAMi 实现亚马逊云科技 Trainium 与 Inferentia 核心级共享与策略性拓扑调度
亚马逊AWS官方博客
·
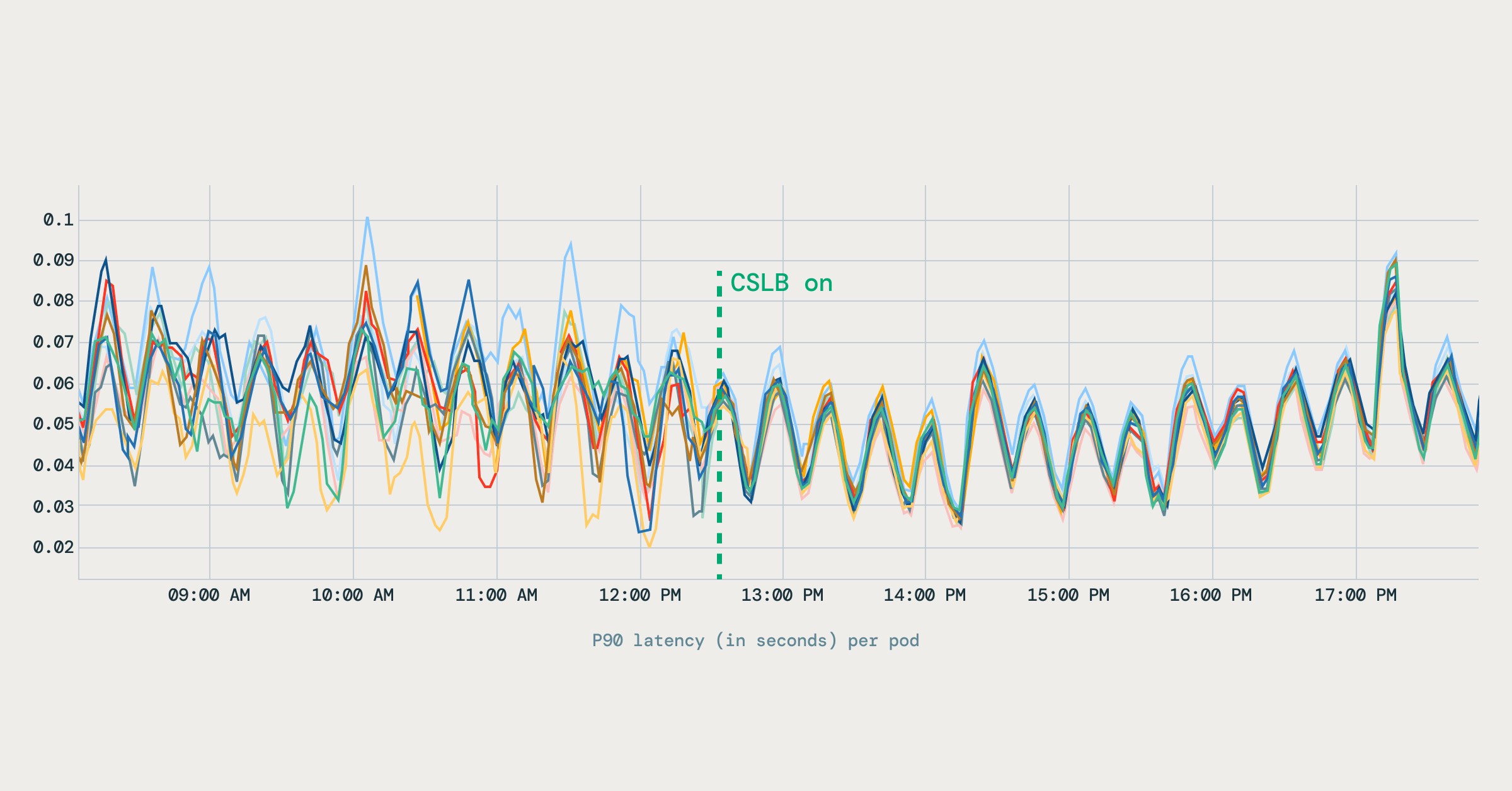
Databricks的智能Kubernetes负载均衡
Databricks
·

Fluid:我们如何构建无服务器计算
Vercel News
·

Kubernetes v1.33:就地Pod调整功能升级为Beta
Kubernetes Blog
·
Kubernetes v1.33:节点存储容量评分用于动态配置(alpha)
Kubernetes Blog
·
