
Databricks的智能Kubernetes负载均衡
内容提要
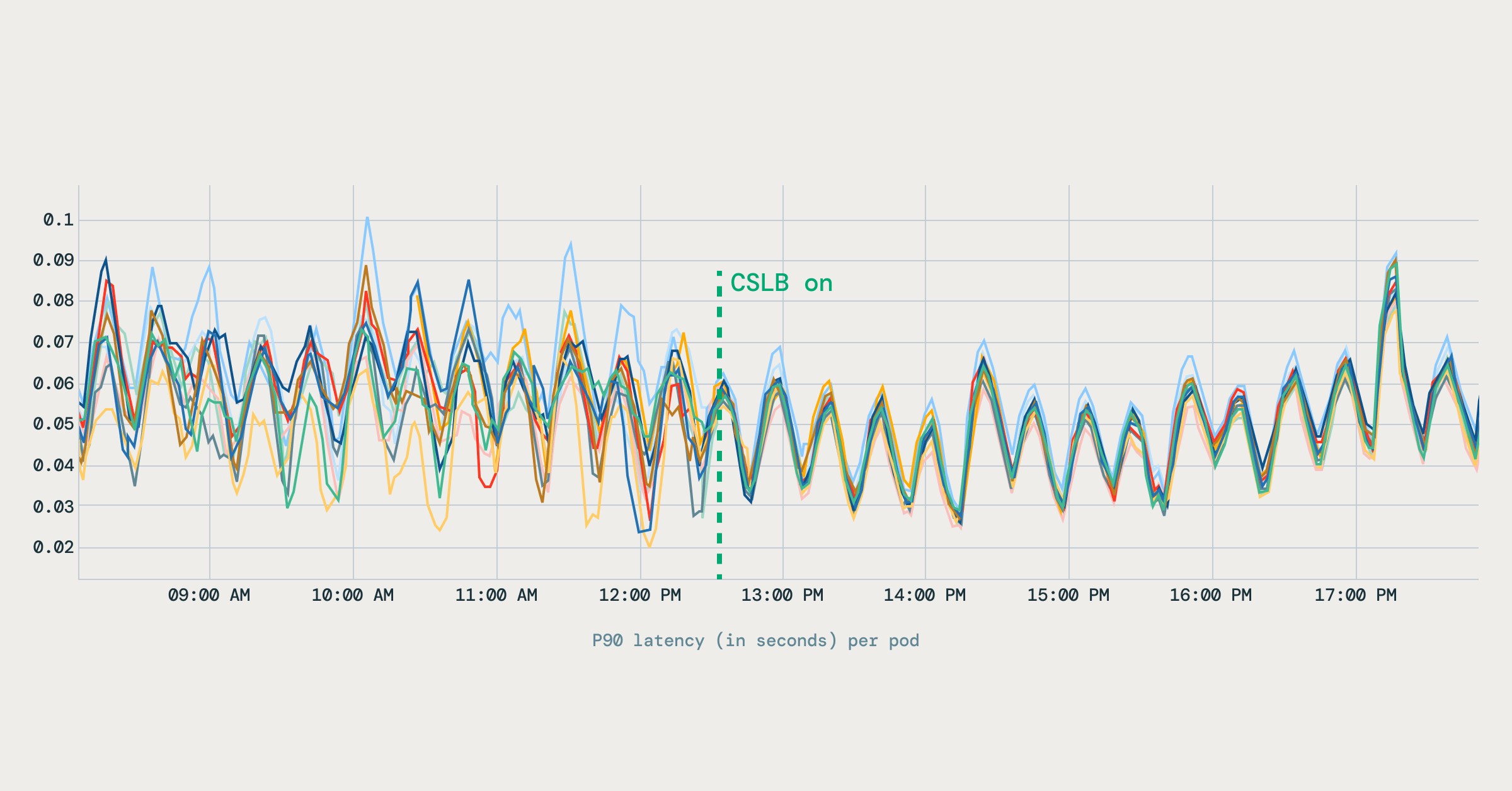
在Databricks,我们开发了智能客户端负载均衡系统,优化Kubernetes中的服务间通信,解决了默认负载均衡的性能和可靠性问题。通过实时服务发现,实现了基于应用层的负载均衡,降低了尾延迟,提高了资源利用率,并支持更复杂的负载均衡策略。
关键要点
-
Databricks开发了智能客户端负载均衡系统,优化Kubernetes中的服务间通信。
-
默认负载均衡在性能和可靠性方面存在局限性,尤其是在高性能服务间通信中。
-
Kubernetes的默认请求路由模型在性能敏感环境中表现不佳,导致尾延迟增加和资源利用率低下。
-
Databricks采用了基于应用层的客户端负载均衡,支持实时服务发现,减少对DNS的依赖。
-
新的负载均衡系统支持更复杂的策略,如基于区域的路由和可插拔的负载均衡策略。
-
通过动态更新健康端点,客户端能够实现一致和高效的负载均衡。
-
系统支持的高级负载均衡策略包括Power of Two Choices和区域亲和性路由。
-
控制平面通过xDS API与Envoy集成,管理外部流量并确保内部和外部路由一致性。
-
这种架构提供了对路由行为的细粒度控制,克服了DNS和kube-proxy的限制。
延伸解读
智能负载均衡的优势
Databricks的智能客户端负载均衡系统通过实时服务发现和应用层负载均衡,显著降低了尾延迟并提高了资源利用率。这种方法不仅解决了传统Kubernetes负载均衡的局限性,还支持更复杂的路由策略,使得服务间通信更加高效和可靠。
与传统负载均衡的对比
传统的Kubernetes负载均衡主要依赖于Layer 4的TCP/IP协议,无法针对HTTP/2等应用层协议进行智能决策。而Databricks的新系统在应用层进行负载均衡,能够根据实时的服务健康状态和流量情况动态调整路由,避免了流量不均和资源浪费的问题。
高级路由策略的应用
Databricks的系统支持多种高级路由策略,如区域亲和性路由和Power of Two Choices。这些策略不仅优化了流量分配,还能有效减少跨区域网络延迟,提升整体服务性能,尤其在地理分布广泛的Kubernetes集群中表现尤为突出。
延伸问答
Databricks的智能负载均衡系统解决了哪些Kubernetes中的问题?
该系统解决了Kubernetes默认负载均衡在性能和可靠性方面的局限性,尤其是在高性能服务间通信中,降低了尾延迟,提高了资源利用率。
Databricks的智能负载均衡系统是如何工作的?
该系统采用基于应用层的客户端负载均衡,支持实时服务发现,动态更新健康端点,实现高效的负载均衡。
与Kubernetes默认负载均衡相比,Databricks的系统有哪些优势?
Databricks的系统支持更复杂的负载均衡策略,如基于区域的路由,能够在每个请求上做出智能决策,减少尾延迟并提高资源利用率。
什么是Power of Two Choices算法,它在负载均衡中有什么作用?
Power of Two Choices算法随机选择两个后端服务器,然后选择负载较低的一个,能够有效实现均匀的流量分配。
Databricks的负载均衡系统如何处理跨区域流量?
该系统支持区域亲和性路由,优先选择本地区域的服务,必要时智能地将流量转移到其他健康区域,以确保高可用性和一致性能。
Databricks的智能负载均衡系统如何与Envoy集成?
该系统通过xDS API与Envoy集成,管理外部流量并确保内部和外部路由的一致性,提供实时的后端端点元数据。
