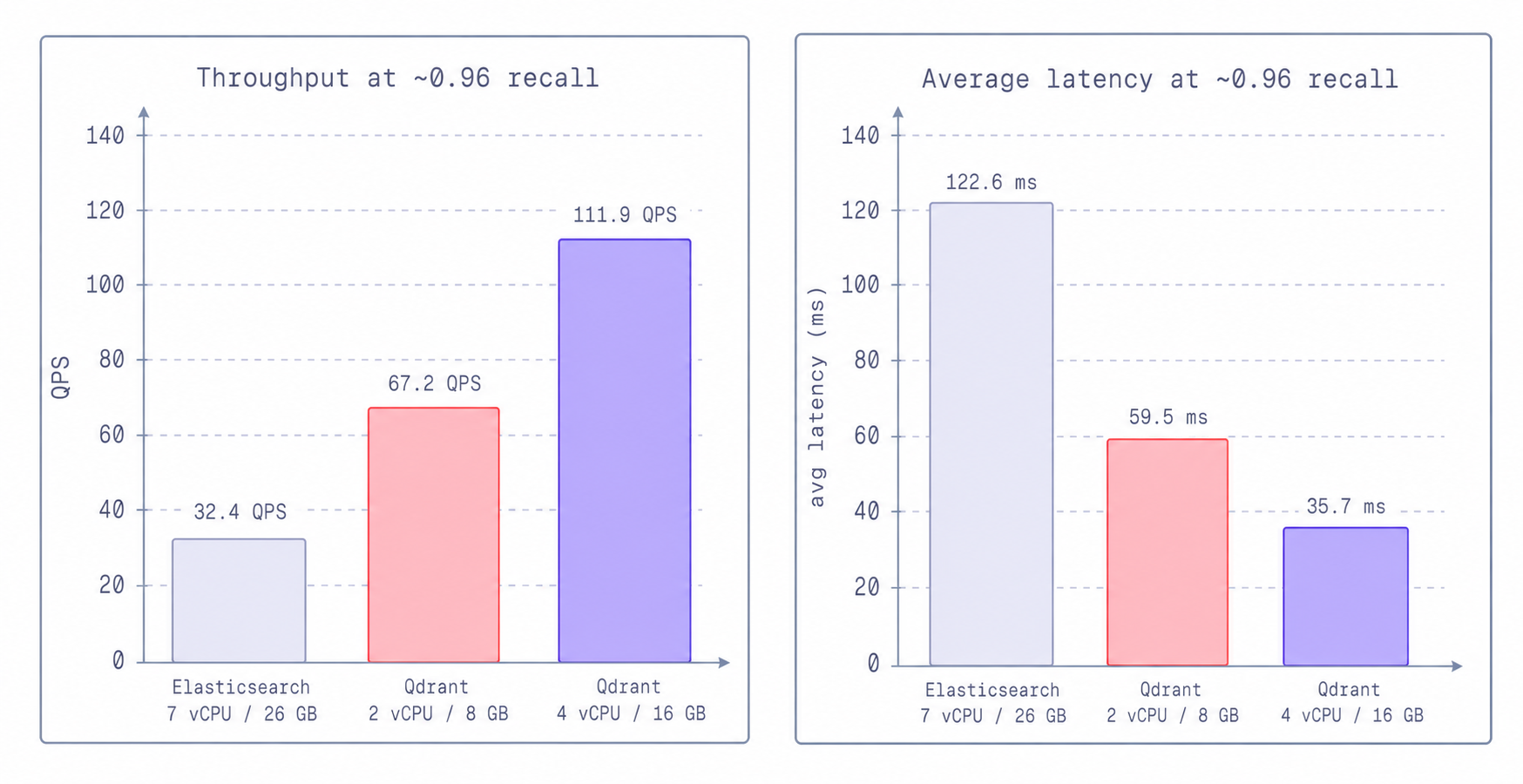
Qdrant在吞吐量上提高了2倍,延迟降低了50%,计算资源减少到1/3,超越了Elastic的DiskBBQ
Qdrant - Vector Database
·

GLM 5.2 Fast现已通过Wafer在AI Gateway上线
Vercel News
·
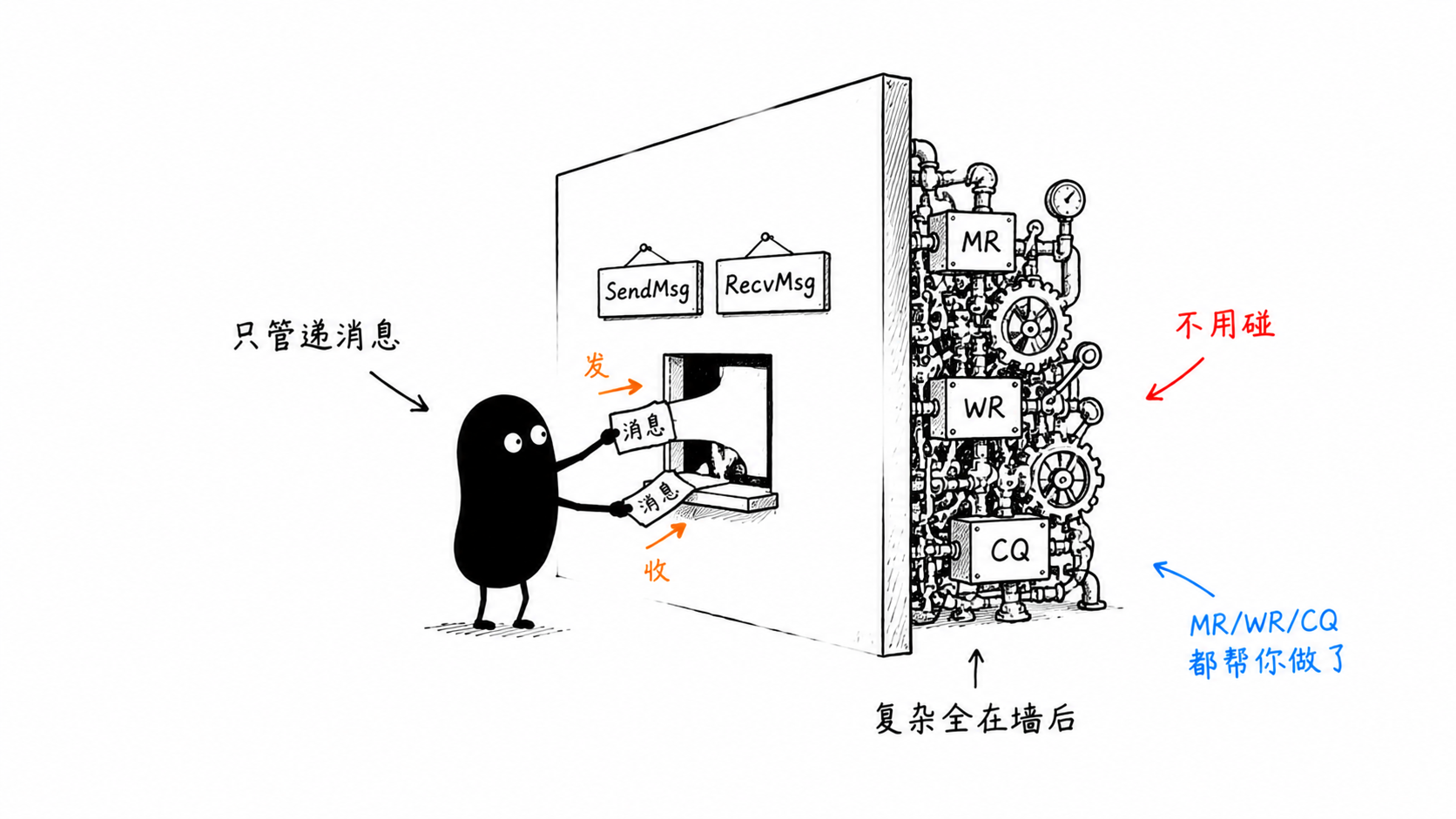
EP217:延迟与吞吐量与带宽
ByteByteGo Newsletter
·

vLLM的Rust前端PR了,预处理吞吐量直接翻了5倍!
迷途小书童
·

DEKRA德凯授予联想消费笔记本Wi-Fi吞吐量3D场型暨路由环境自适应专项认证
全球TMT-美通国际
·

在AI Gateway上按成本、延迟或吞吐量对提供者进行排序
Vercel News
·
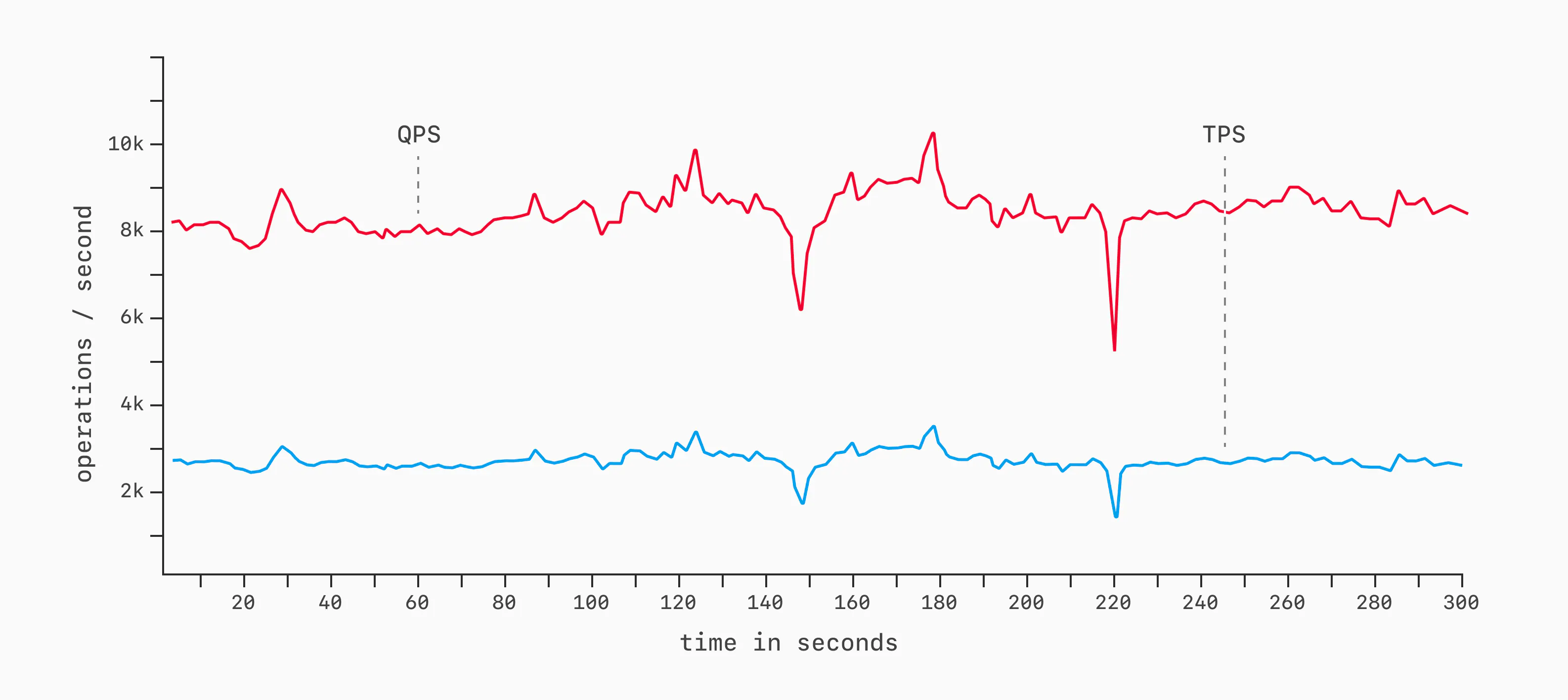
关于基准测试
PlanetScale - Blog
·