
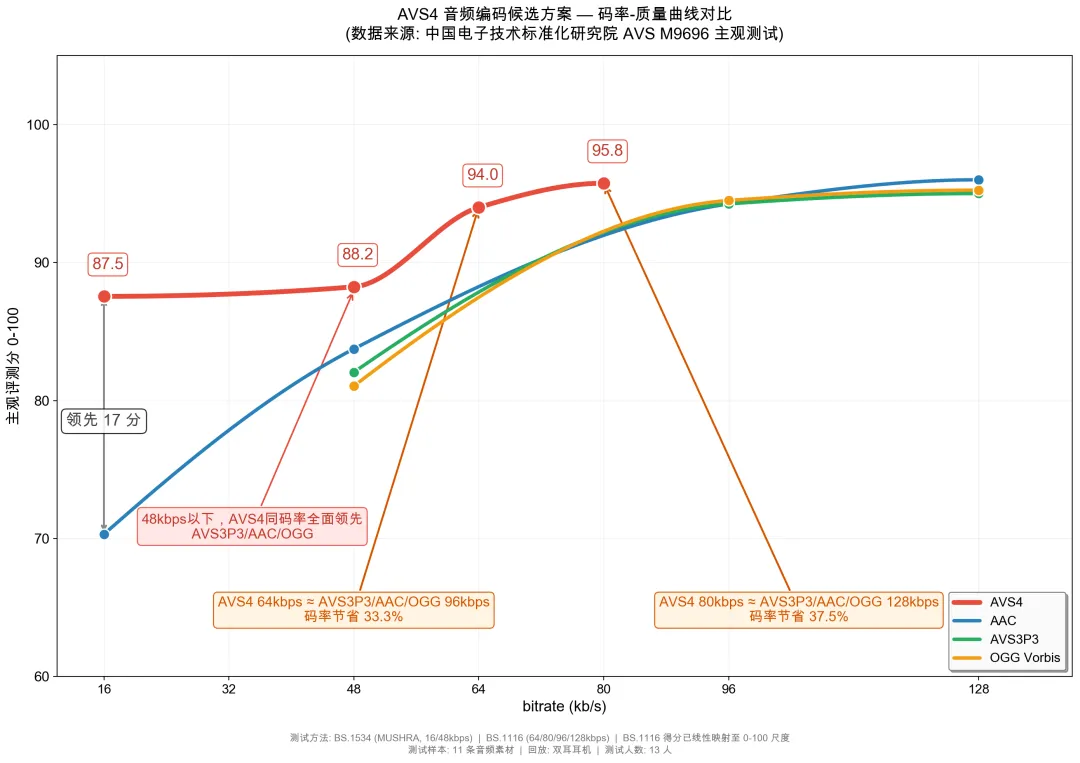
音乐流媒体的下一个“听觉革命”:腾讯音乐NAC通过AVS官方验收
实时互动网
·

电视的沙沙声
Another Dayu
·

AI 可穿戴听觉设备:从聆听设备到智能伴侣
实时互动网
·
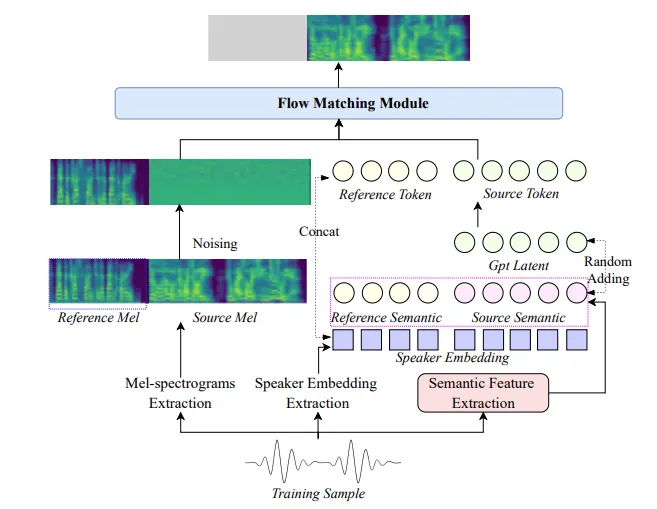
IndexTTS2:用极致表现力颠覆听觉体验
实时互动网
·


通过战略性听觉刺激提升认知表现
DEV Community
·
