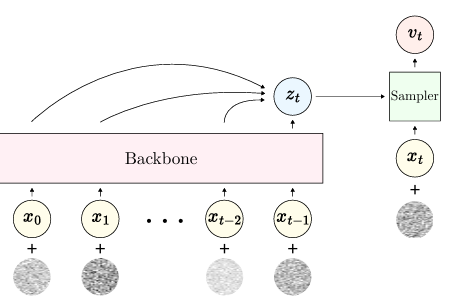
自回归模型(CAM)在生成离散标记序列时存在错误累积问题。研究提出了一种噪声增强策略,以模拟推理错误,从而提升生成质量。CAM在音乐生成任务中优于传统模型,为实时音频应用提供了更高质量的序列生成基础。
本文探讨了自动语音识别中的基准测试数据价值,发现噪声增强可提升模型性能。研究提出了多语言模型SQuId和AudioPaLM,展示了其在不同语言环境下的优势。同时,引入AIR-Bench评估音频语言模型的能力,揭示现有模型的局限性。此外,开发了SD-Eval和AudioBench基准,评估口语对话和语音模型的表现,为未来研究提供方向。
完成下面两步后,将自动完成登录并继续当前操作。