
噪声增强 CAM(连续自回归模型):推进实时音频生成
内容提要
自回归模型(CAM)在生成离散标记序列时存在错误累积问题。研究提出了一种噪声增强策略,以模拟推理错误,从而提升生成质量。CAM在音乐生成任务中优于传统模型,为实时音频应用提供了更高质量的序列生成基础。
关键要点
-
自回归模型(CAM)在生成离散标记序列时存在错误累积问题。
-
研究提出了一种噪声增强策略,以模拟推理错误,从而提升生成质量。
-
CAM在音乐生成任务中优于传统模型,提供了更高质量的序列生成基础。
-
连续自回归模型面临序列生成质量下降的挑战,主要由于推理过程中的错误积累。
-
传统自回归模型依赖于VQ-VAE进行数据离散化,但存在额外损失和复杂性的问题。
-
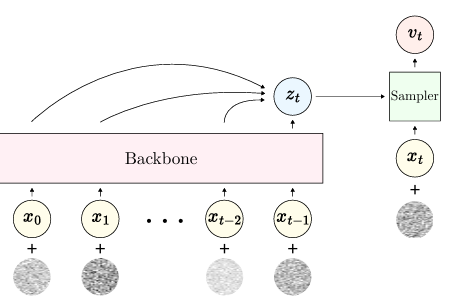
CAM通过向序列中注入噪声来抵消误差累积,结合了整流流和自回归模型的优势。
-
CAM经过预先训练,能够在生成较长序列时抵御错误累积,提高生成序列的质量。
-
研究使用约20,000个单乐器录音的数据集进行训练和评估,表现优于其他模型。
-
所提出的方法为实时和交互式音频应用开辟了道路,具有重要的研究价值。
延伸解读
噪声增强策略的意义
噪声增强策略通过模拟推理错误,帮助连续自回归模型(CAM)在生成过程中抵消错误累积。这一方法不仅提升了生成序列的质量,还为实时音频应用提供了更可靠的基础,尤其在音乐生成领域表现突出。
与传统模型的比较
CAM相较于传统自回归模型,避免了VQ-VAE带来的额外损失和复杂性。通过直接在连续嵌入上训练,CAM能够更高效地生成音频序列,尤其在处理长序列时,表现出更强的稳定性和质量。
应用前景与挑战
CAM为实时和交互式音频应用开辟了新的可能性,但仍需关注其在不同音频类型和复杂场景下的表现。未来的研究可以进一步探索如何优化噪声注入技术,以提升生成质量和效率。
延伸问答
什么是连续自回归模型(CAM)?
连续自回归模型(CAM)是一种用于生成离散标记序列的模型,它通过顺序生成嵌入来处理音频和音乐生成任务。
CAM如何解决错误累积问题?
CAM通过在训练过程中引入噪声增强策略,模拟推理错误,从而抵消错误累积,提高生成序列的质量。
CAM在音乐生成任务中的表现如何?
CAM在音乐生成任务中表现优于传统模型,提供了更高质量的序列生成基础。
传统自回归模型的缺点是什么?
传统自回归模型依赖于VQ-VAE进行数据离散化,导致额外损失和复杂性,且在推理过程中容易出现错误累积。
CAM的训练数据集是什么?
CAM使用约20,000个单乐器录音的数据集进行训练和评估,这些录音具有48 kHz的立体声音频。
噪声增强策略的作用是什么?
噪声增强策略通过向序列中注入噪声,模拟推理过程中的错误,从而提高生成序列的质量。
