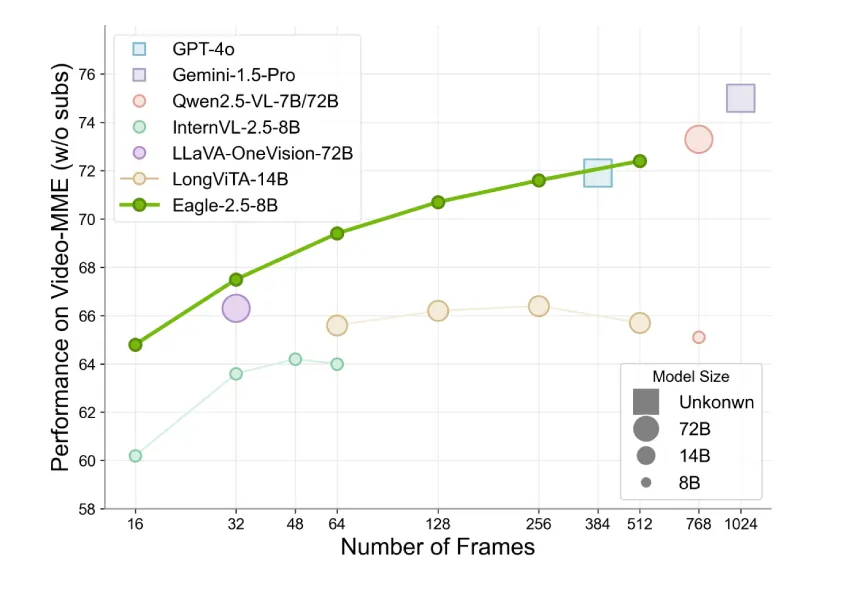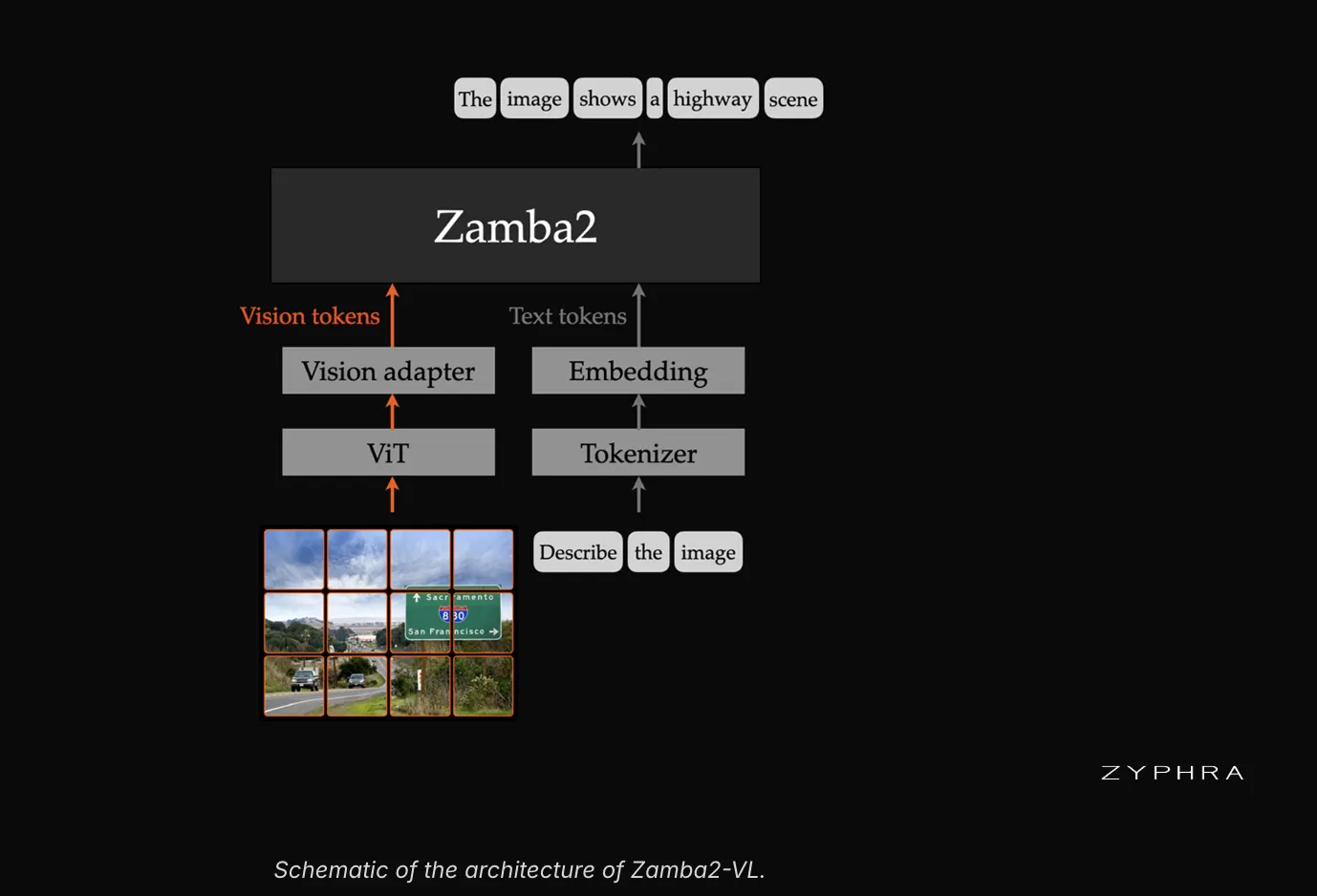
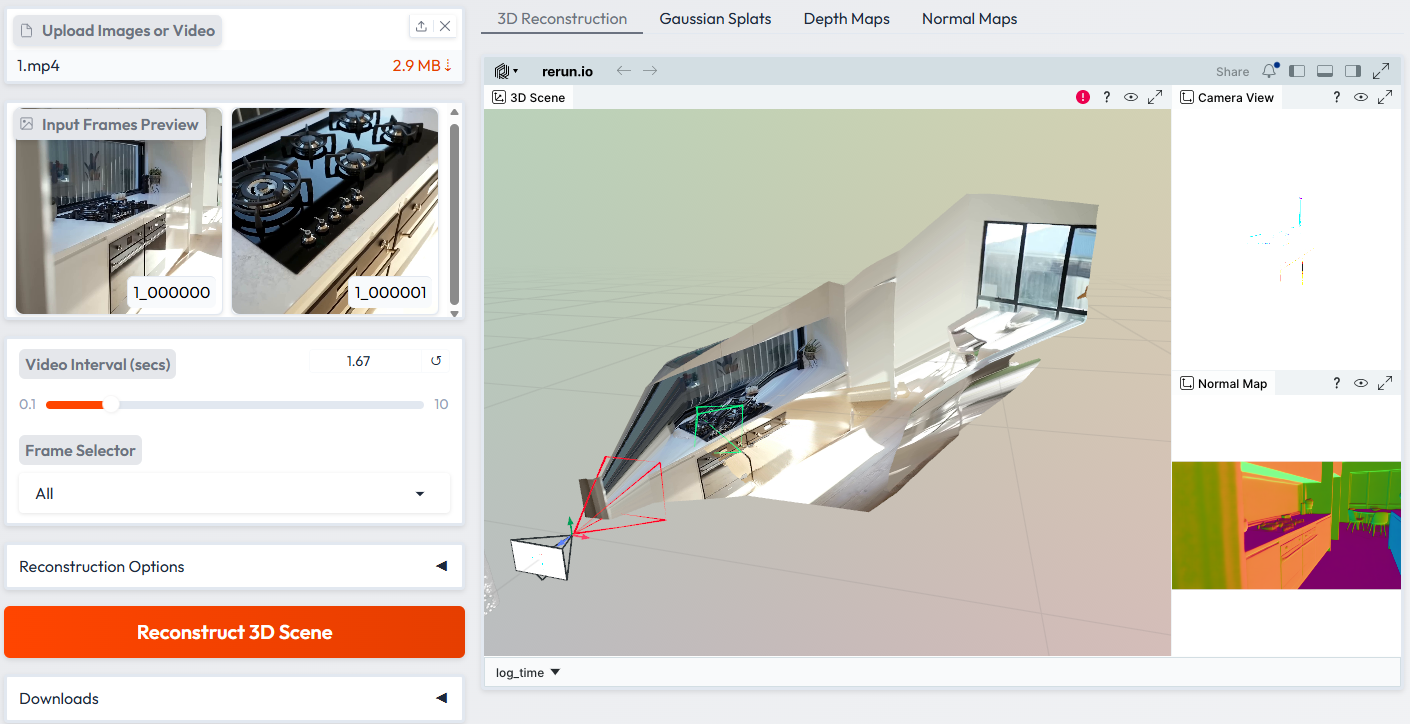


苹果分享iOS 26即将推出的人工智能基础模型细节
InfoQ
·

谷歌发布MedGemma:用于医疗文本和图像分析的开源AI模型
InfoQ
·

如何在本地安装Meta Perception LM 8B?
DEV Community
·