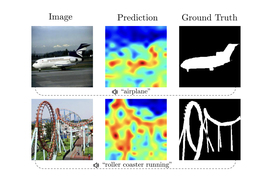
麻省理工学院研究人员开发了一种新方法,提升人工智能模型在视觉和听觉学习方面的能力。该方法能够自动检索视频和音频数据,改善机器人对真实环境的理解。研究团队创建了无需人工标注的模型,能更精确地对齐音视频数据,提高视频检索和场景分类的准确性。未来,他们希望将此技术应用于日常工具中。
麻省理工学院的研究人员开发了一种新型机器学习模型,能够同时处理音频和视觉数据,提升机器人与现实世界的互动能力。该模型通过优化视频帧与音频的对应关系,提高了视频检索和音视频场景分类的准确性,未来有望应用于新闻和电影制作等领域。
本文介绍了利用Copernicus计划的Sentinel卫星和Google Earth Engine构建的180,662个样本数据集,支持深度学习算法在场景分类和地表映射中的应用。研究涵盖野火识别、土地利用分类及水资源监测,提出了多模态机器学习方法,强调多光谱指数在火灾管理中的有效性,并提供了基准测试和优化建议。
完成下面两步后,将自动完成登录并继续当前操作。