
人工智能无需人类干预即可学习视觉与声音的关联
内容提要
麻省理工学院的研究人员开发了一种新型机器学习模型,能够同时处理音频和视觉数据,提升机器人与现实世界的互动能力。该模型通过优化视频帧与音频的对应关系,提高了视频检索和音视频场景分类的准确性,未来有望应用于新闻和电影制作等领域。
关键要点
-
麻省理工学院的研究人员开发了一种新型机器学习模型,能够同时处理音频和视觉数据,提升机器人与现实世界的互动能力。
-
该模型通过优化视频帧与音频的对应关系,提高了视频检索和音视频场景分类的准确性。
-
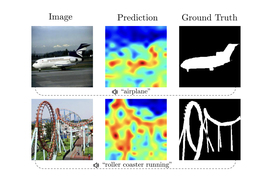
研究人员在训练过程中将音频分割成更小的窗口,以生成与每个音频窗口对应的独立表示。
-
新模型CAV-MAE Sync能够在没有人工标签的情况下对视频片段中的音频和视觉数据进行对齐。
-
该模型的改进使其在基于音频查询检索视频和预测音视频场景类别方面表现更为准确。
-
未来,该技术有望应用于新闻和电影制作等领域,帮助自动化多模态内容的策划。
延伸解读
技术背景与发展
麻省理工学院的研究展示了机器学习在音频与视觉数据处理上的新进展。通过无须人工标签的训练方式,CAV-MAE Sync模型能够更精准地对齐音视频数据,这一技术的突破为未来的多模态内容生成奠定了基础,尤其在新闻和电影制作等领域具有广泛应用潜力。
模型的创新与优势
CAV-MAE Sync模型通过将音频分割成更小的窗口,提升了音视频数据的对应关系学习能力。这种细粒度的学习方式使得模型在视频检索和场景分类任务中表现更为出色,显示出相较于传统方法的明显优势,尤其是在处理复杂音视频场景时。
未来应用与挑战
尽管CAV-MAE Sync在音视频处理上取得了显著进展,但将其应用于实际场景仍面临挑战。如何有效整合文本数据以实现更全面的多模态理解,将是未来研究的重要方向。此外,模型的普适性和适应性也需进一步验证,以确保其在不同领域的有效性。
延伸问答
CAV-MAE Sync模型的主要功能是什么?
CAV-MAE Sync模型能够在没有人工标签的情况下对视频片段中的音频和视觉数据进行对齐,提升视频检索和音视频场景分类的准确性。
该研究如何提高机器学习模型的性能?
研究通过优化视频帧与音频的对应关系和引入新的数据表示,改善了模型在音频查询检索视频和预测音视频场景类别方面的表现。
CAV-MAE Sync模型与之前的模型有什么不同?
CAV-MAE Sync模型通过将音频分割成更小的窗口,生成独立的表示,从而实现更精细的音频与视频帧的对应关系。
该技术未来可能应用于哪些领域?
该技术有望应用于新闻和电影制作等领域,帮助自动化多模态内容的策划。
研究人员如何训练CAV-MAE Sync模型?
研究人员通过将音频分割成小窗口,并在训练过程中学习每个视频帧与相应音频的关系来训练模型。
CAV-MAE Sync模型的创新之处在哪里?
模型的创新在于引入了对比目标和重建目标,使其能够更独立地处理音频和视觉数据,从而提升整体性能。
