本文介绍了如何使用变换器模型生成文本嵌入,文本嵌入是文本的数值表示,能够捕捉语义。通过预训练的BERT模型,可以生成高质量的上下文嵌入。文章还探讨了均值池化和句子变换器库等技术,以提高嵌入质量,从而帮助计算机理解文本并执行自然语言处理任务。
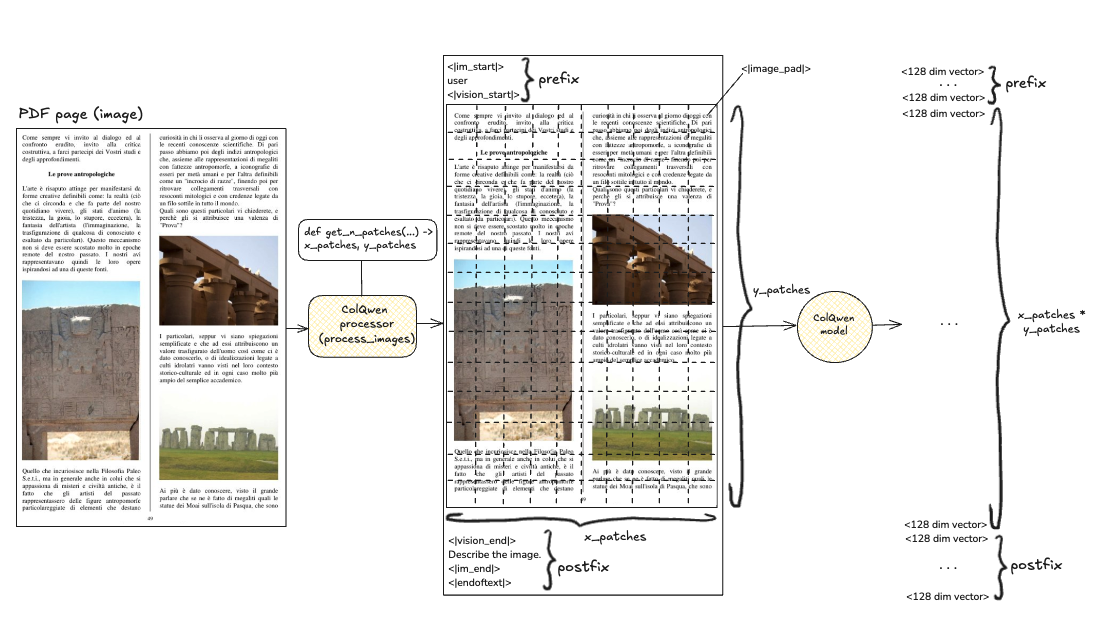
本文介绍了使用Qdrant和VLLMs(如ColPali和ColQwen)进行高效PDF文档检索的方法。与传统依赖OCR的PDF检索相比,VLLMs能够直接处理PDF页面,显著提高检索性能。为了解决大规模检索中的计算密集问题,建议通过均值池化减少向量数量,从而加快索引和检索速度。实验结果表明,该方法在PDF检索中具有显著的性能提升,适合在工作流中实施。
完成下面两步后,将自动完成登录并继续当前操作。