
多向量文档检索
内容提要
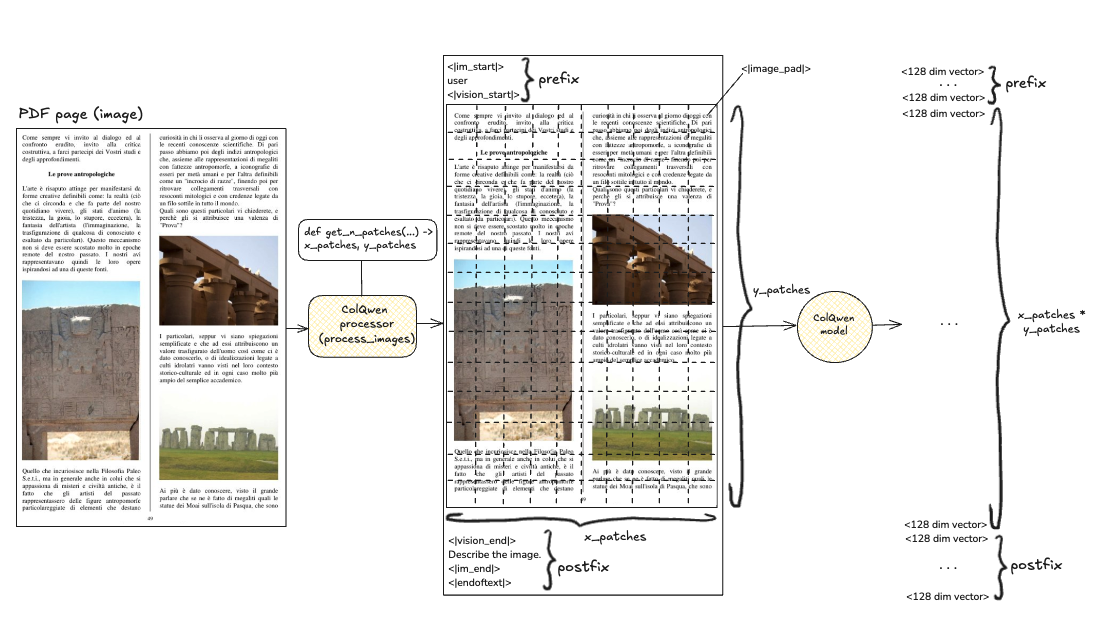
本文介绍了使用Qdrant和VLLMs(如ColPali和ColQwen)进行高效PDF文档检索的方法。与传统依赖OCR的PDF检索相比,VLLMs能够直接处理PDF页面,显著提高检索性能。为了解决大规模检索中的计算密集问题,建议通过均值池化减少向量数量,从而加快索引和检索速度。实验结果表明,该方法在PDF检索中具有显著的性能提升,适合在工作流中实施。
关键要点
-
使用Qdrant和VLLMs(如ColPali和ColQwen)可以高效检索PDF文档。
-
与传统的OCR方法相比,VLLMs能够直接处理PDF页面,显著提高检索性能。
-
VLLMs生成的重向量表示使得PDF检索在大规模时计算密集,需进行优化。
-
建议通过均值池化减少PDF页面表示中的向量数量,以加快索引和检索速度。
-
实验结果表明,均值池化方法在索引时间和检索质量上均有显著提升。
-
该方法适合在工作流中实施,以避免长时间的索引和慢速检索问题。
延伸解读
VLLMs的优势与局限
VLLMs(如ColPali和ColQwen)在PDF文档检索中展现出显著优势,能够直接处理PDF页面,避免了传统OCR方法的复杂性。然而,这些模型生成的重向量表示在大规模检索时会导致计算密集,需进行优化。用户在选择使用VLLMs时,应权衡其高效性与计算资源的需求。
均值池化的实用性
均值池化作为一种优化手段,可以有效减少PDF页面表示中的向量数量,从而加快索引和检索速度。实验结果表明,采用均值池化后,索引时间显著缩短,同时检索质量保持在较高水平。这一方法适合在需要处理大量PDF文档的工作流中实施。
实施中的注意事项
在实施VLLMs进行PDF检索时,需关注计算资源的配置,尤其是在低资源环境下,建议使用较小的批量大小进行嵌入和均值池化。此外,优化检索过程是确保系统性能的关键,忽视这一点可能导致检索速度缓慢,影响用户体验。
延伸问答
如何使用Qdrant和VLLMs进行PDF文档检索?
可以通过使用Qdrant和VLLMs(如ColPali和ColQwen)来高效检索PDF文档,这些模型直接处理PDF页面,无需预处理。
VLLMs与传统OCR方法相比有什么优势?
VLLMs能够直接处理PDF页面,显著提高检索性能,而传统OCR方法依赖于复杂的预处理和解析,效率较低。
如何优化VLLMs在大规模PDF检索中的计算效率?
建议通过均值池化减少PDF页面表示中的向量数量,从而加快索引和检索速度。
均值池化在PDF检索中的作用是什么?
均值池化通过平均化多个向量,减少向量数量,同时保留重要信息,从而提高检索效率和质量。
实验结果如何验证该方法的有效性?
实验表明,均值池化方法在索引时间上提高了一个数量级,检索质量与原模型相当,验证了其有效性。
在实施PDF检索时需要注意哪些问题?
需要注意长时间的索引和慢速检索问题,建议实施优化方法以确保系统的高效性和可扩展性。
