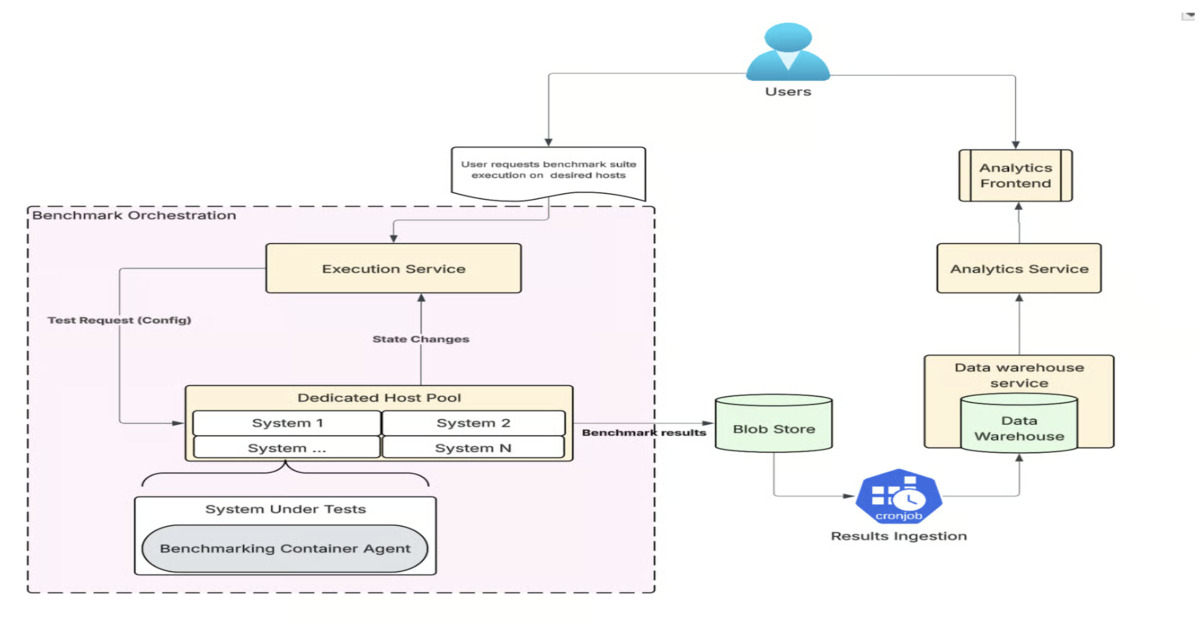
Uber推出了Ceilometer,一个内部自适应基准框架,用于评估基础设施性能。该系统自动化基准测试,提供一致的数据驱动性能信号,帮助识别性能回归和配置低效。Ceilometer支持多种工作负载类型,并计划集成AI以优化资源和检测异常,从而提升基础设施决策效率。
本文提出了时间序列健身房,作为评估人工智能代理在时间序列机器学习中的基准框架,旨在填补现有基准的不足,提高AI代理评估的相关性和实用性。
本研究评估了大型语言模型(LLM)推理过程的环境影响,提出了一种新基准框架,量化了30种先进模型在商业数据中心的资源消耗。结果表明,尽管单次查询的能效较高,但全球应用导致了巨大的资源消耗,强调了可持续性评估的重要性。
本文探讨了大型语言模型中的偏见问题,提出了一种可扩展的基准框架,通过多任务方法检测社会文化维度的偏见,并利用大型语言模型进行自动评估。研究揭示了模型大小与安全性之间的权衡,为未来更公平的语言模型发展提供指导。
本研究提出了MLLMU-Bench基准框架,以解决多模态大语言模型在隐私保护方面的不足。研究发现,单模态遗忘算法在生成和填空任务中表现优异,而多模态遗忘方法在分类任务中更有效。
完成下面两步后,将自动完成登录并继续当前操作。