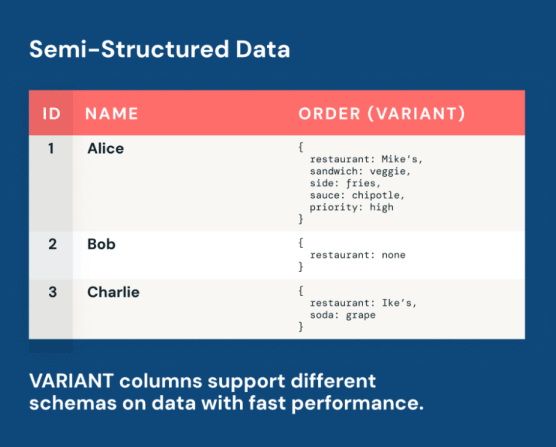
Databricks的Iceberg v3进入公测,支持增量数据处理和半结构化数据分析,简化数据管道。新特性包括行血统、删除向量和VARIANT类型,提升性能,支持多引擎互操作性,优化数据治理,降低维护成本。
本文讨论了使用Apache Hudi进行增量数据处理的方法,以及它如何弥合批处理和流处理之间的差距。文章解释了数据架构的演变,数据仓库和数据湖之间的区别,以及Hudi的组件。文章还强调了增量处理的需求,并提供了Hudi如何实现规模化增量ETL的用例和示例。文章讨论了合并、索引、聚类和压缩等优化增量处理的功能。文章最后提到了Hudi社区和可用资源。
完成下面两步后,将自动完成登录并继续当前操作。