
开放湖仓的下一个时代:Databricks上Apache Iceberg™ v3公测
内容提要
Databricks的Iceberg v3进入公测,支持增量数据处理和半结构化数据分析,简化数据管道。新特性包括行血统、删除向量和VARIANT类型,提升性能,支持多引擎互操作性,优化数据治理,降低维护成本。
关键要点
-
Databricks的Iceberg v3进入公测,支持增量数据处理和半结构化数据分析。
-
Iceberg v3引入行血统、删除向量和VARIANT类型,提升性能和互操作性。
-
行血统帮助快速识别数据变化,删除向量提高数据操作性能。
-
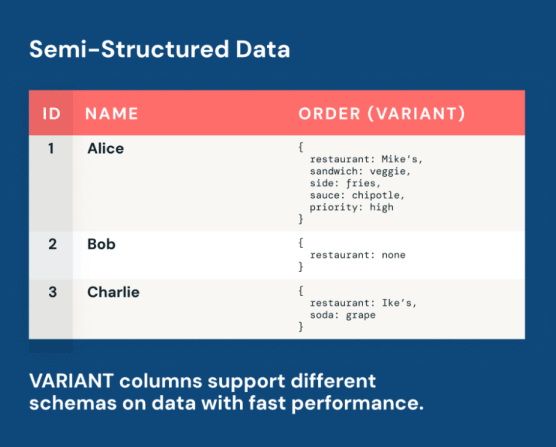
VARIANT类型允许半结构化数据与关系型列共存,简化数据处理。
-
Unity Catalog实现多引擎和多目录的互操作性,优化数据治理。
-
Delta Lake与Iceberg的互操作性增强,简化数据管理。
-
Databricks提供自动化性能优化,减少操作开销。
延伸解读
增量数据处理的优势
Iceberg v3引入的行血统和删除向量显著提升了增量数据处理的效率。通过快速识别数据变化,团队可以专注于处理实际变更,避免了传统方法中全表扫描的高成本和低效率。这一特性对于需要实时数据分析的企业尤为重要,能够加速数据洞察的获取。
半结构化数据的处理简化
VARIANT类型的引入使得半结构化数据可以与关系型数据共存,简化了数据处理流程。数据团队不再需要为每次数据结构变化而调整管道,能够直接使用标准SQL进行查询。这种灵活性对于快速变化的业务环境尤为重要,能够提高数据分析的响应速度。
多引擎互操作性的提升
Unity Catalog的推出使得不同数据引擎和目录之间的互操作性大幅提升。企业可以在多个平台上无缝访问数据,避免了数据重复和孤岛问题。这种统一的治理和访问控制不仅提高了数据安全性,也为数据团队提供了更大的灵活性,能够更高效地利用现有资源。
延伸问答
Iceberg v3的新特性有哪些?
Iceberg v3引入了行血统、删除向量和VARIANT类型,支持增量数据处理和半结构化数据分析。
行血统和删除向量如何提升数据处理性能?
行血统帮助快速识别数据变化,删除向量提高数据操作性能,使数据操作速度比传统方法快10倍。
VARIANT类型在Iceberg v3中有什么作用?
VARIANT类型允许半结构化数据与关系型列共存,简化数据处理,无需进行模式迁移。
Unity Catalog如何优化数据治理?
Unity Catalog实现跨目录和引擎的互操作性,提供细粒度访问控制,简化数据治理和监控。
Databricks如何支持多引擎互操作性?
Databricks通过Unity Catalog支持多引擎互操作性,允许不同平台的数据访问和管理。
Iceberg v3如何处理增量数据?
Iceberg v3通过行血统和删除向量,支持高效的增量数据处理,专注于处理实际变化的数据。
