


使用 Amazon S3 Tables 优化数据湖:从Hudi 迁移到托管 Iceberg
亚马逊AWS官方博客
·
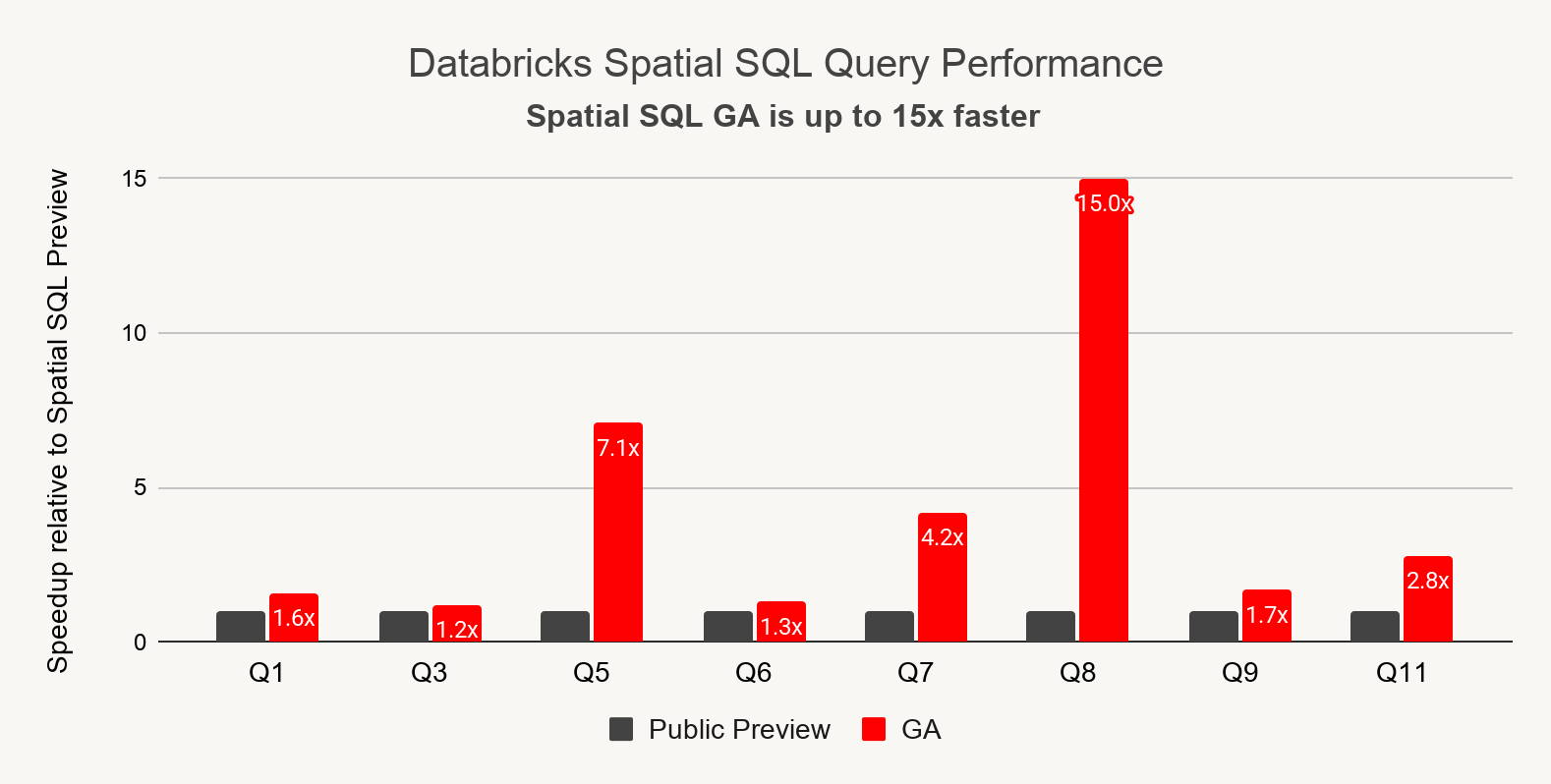
地理空间无限:支持AI/BI地图的空间SQL GA、Delta Sharing和Iceberg v3
Databricks
·
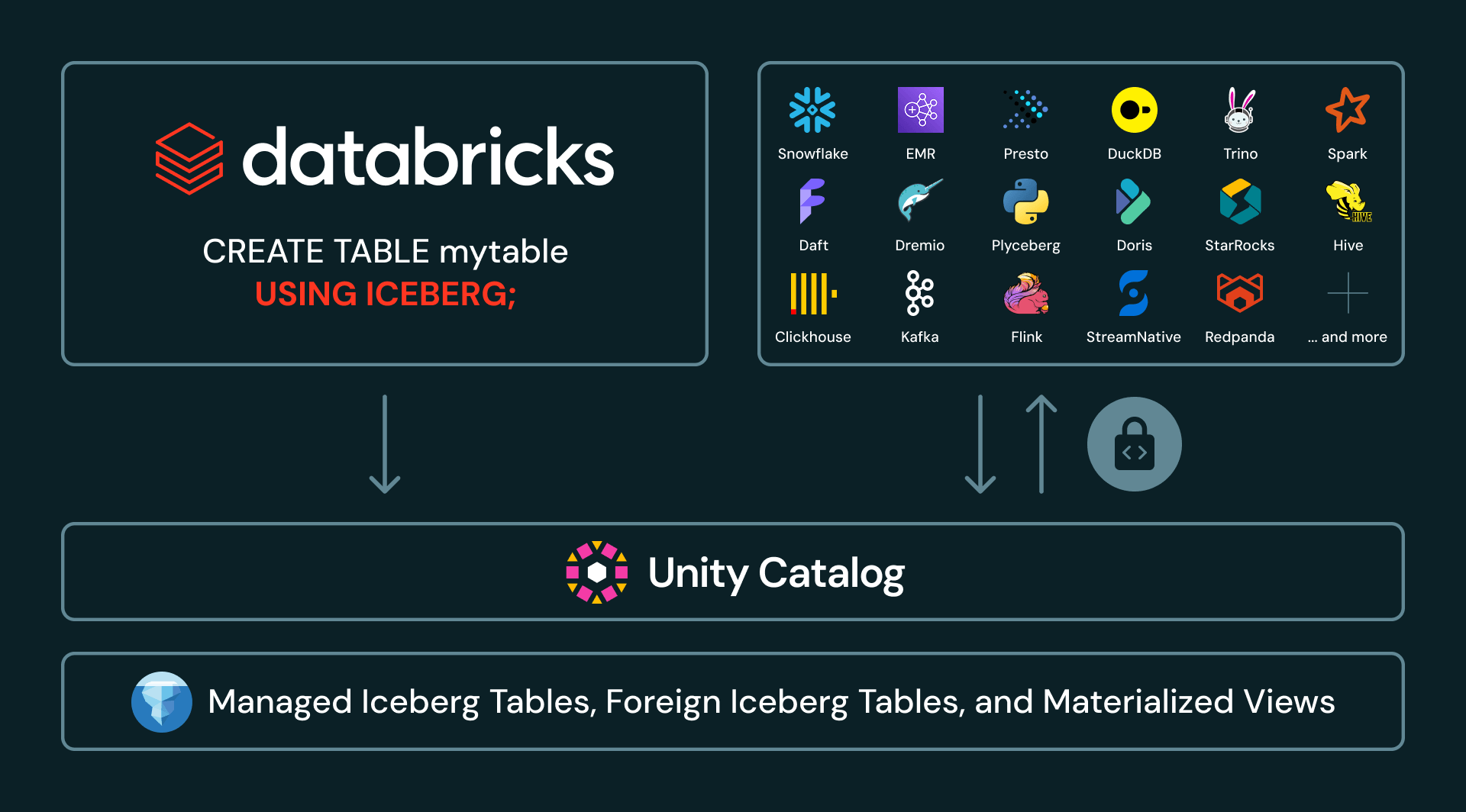
Unity Catalog 与 Apache Iceberg™ 的下一个时代
Databricks
·

ASF项目聚焦:Apache Iceberg
The Apache Software Foundation Blog
·

Postgres到Iceberg仅需13分钟:Supermetal与Flink、Kafka Connect和Spark的比较
The New Stack
·
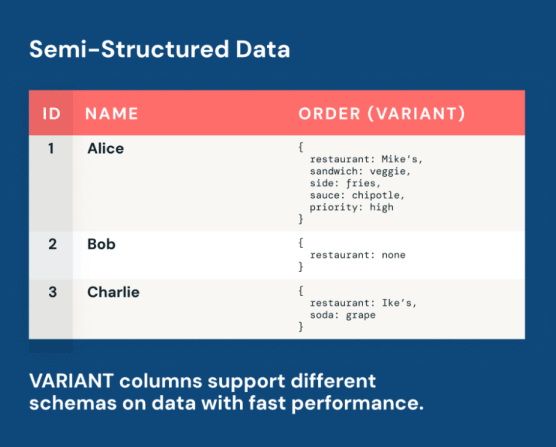
开放湖仓的下一个时代:Databricks上Apache Iceberg™ v3公测
Databricks
·
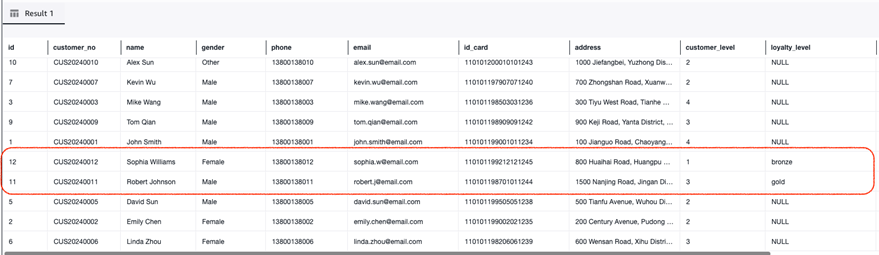
S3 Tables 实战:两种方案,把 MySQL 数据实时”搬”进 S3 Tables
亚马逊AWS官方博客
·

