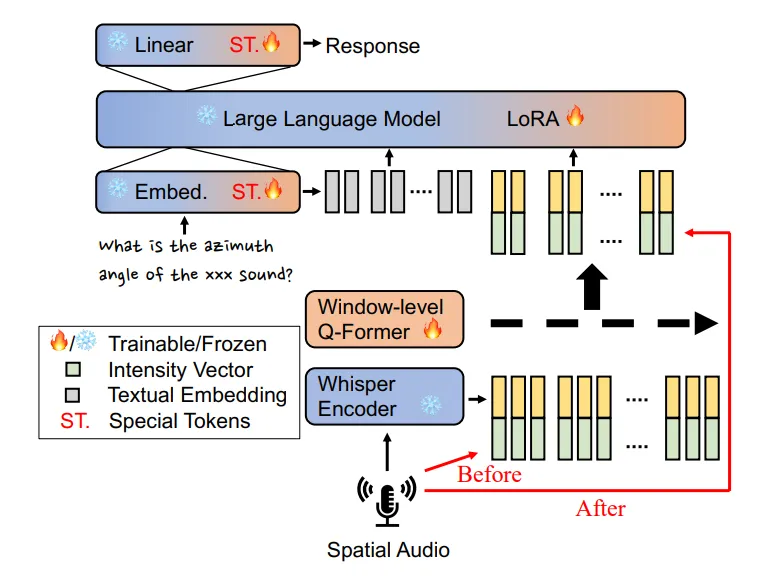
清华、剑桥与字节跳动的研究团队提出了一种新方法,使大语言模型(LLM)能够理解空间音频,具备声音源定位、远场语音识别和基于定位的语音提取能力。实验结果表明,该模型在空间音频任务中的表现显著提升,展示了LLM在复杂三维场景感知方面的潜力,为未来AI应用奠定了基础。
本文提出了一种自监督框架,用于音频-视觉表示学习,显著提升了视频中声音源定位的效果。通过数据增强和新约束条件,模型在多个基准测试中表现优异,尤其在音频与视觉的对应学习和动作识别任务中取得了最先进的结果。
完成下面两步后,将自动完成登录并继续当前操作。