
大语言模型能够理解空间音频吗?
内容提要
清华、剑桥与字节跳动的研究团队提出了一种新方法,使大语言模型(LLM)能够理解空间音频,具备声音源定位、远场语音识别和基于定位的语音提取能力。实验结果表明,该模型在空间音频任务中的表现显著提升,展示了LLM在复杂三维场景感知方面的潜力,为未来AI应用奠定了基础。
关键要点
-
清华、剑桥与字节跳动的研究团队提出了一种新方法,使大语言模型(LLM)理解空间音频。
-
该方法使LLM具备声音源定位、远场语音识别和基于定位的语音提取能力。
-
研究围绕三个核心任务展开:声音源定位(SSL)、远场语音识别(FSR)和基于定位的语音提取(LSE)。
-
在声音源定位方面,模型的平均角度误差从6.6度降至2.7度,显示出显著提升。
-
结合空间特征后,远场语音识别的词错误率进一步降低,证明了LLM的理解能力提升。
-
在基于定位的语音提取任务中,模型能够有效区分和提取指定方向的声音。
-
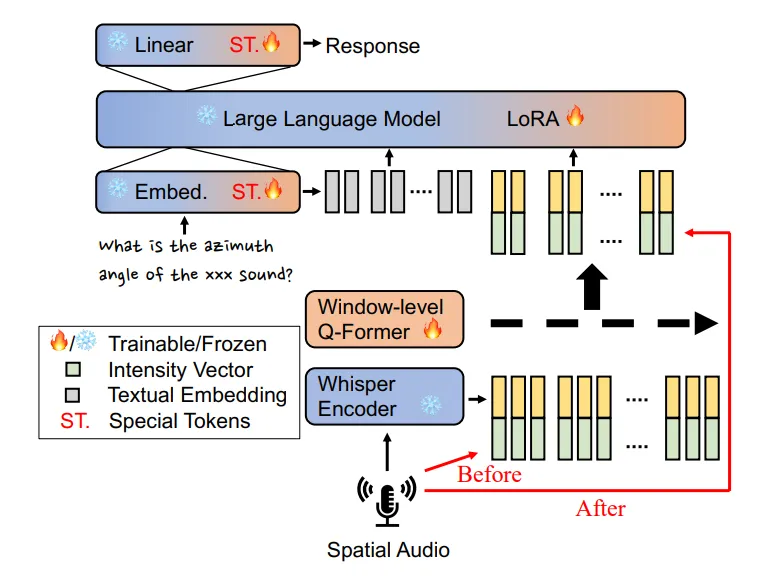
研究团队选择冻结主流Whisper语音编码器和LLM,仅微调对齐模块和特定层。
-
空间信息的注入点选择在模型的中间层,效果优于末端融合。
-
研究合成了大量复杂空间音频数据,支持LLM学习空间感知和多声源分离。
-
整体实验展示了LLM在空间听觉理解和复杂三维场景感知上的潜力,为AI未来的应用奠定基础。
延伸解读
空间音频的应用前景
随着大语言模型(LLM)对空间音频理解能力的提升,未来在虚拟现实、增强现实等领域的应用将更加广泛。LLM能够识别声音源的方向和位置,这为沉浸式体验提供了技术支持,可能改变用户与环境的互动方式。
技术实现的关键
研究团队通过将空间音频的四通道特征引入LLM,显著提高了声音源定位的准确性。这一创新方法强调了中间层的空间信息注入点选择,显示出在模型设计中,如何有效利用空间特征是提升性能的关键。
多声源环境下的挑战
尽管模型在多声源环境中表现出色,但仍需关注其在极端复杂场景下的表现。随着应用场景的多样化,如何进一步提升模型在噪声干扰和语音重叠情况下的识别能力,将是未来研究的重要方向。
延伸问答
大语言模型如何理解空间音频?
研究团队提出了一种新方法,使大语言模型具备声音源定位、远场语音识别和基于定位的语音提取能力。
声音源定位的实验结果如何?
模型在声音源定位任务中的平均角度误差从6.6度降至2.7度,显示出显著提升。
远场语音识别的表现如何?
结合空间特征后,远场语音识别的词错误率进一步降低,证明了LLM的理解能力提升。
基于定位的语音提取任务的能力是什么?
模型能够根据指令有效区分和提取指定方向的声音,即使在多个说话者同时存在的情况下。
研究团队在模型训练中采取了什么方法?
团队选择冻结主流Whisper语音编码器和LLM,仅微调对齐模块和特定层。
这项研究对未来AI应用有什么意义?
研究展示了LLM在空间听觉理解和复杂三维场景感知上的潜力,为AI未来的应用奠定基础。
