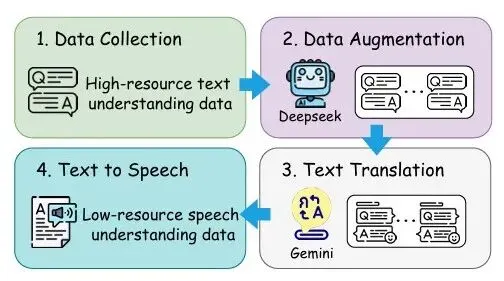
本文提出了一种针对低资源语言(如泰语)的语音大语言模型(SLLM)多任务理解方案,核心创新包括自监督学习的语音编码器XLSR-Thai、通用语音-文本对齐方法U-Align,以及泰语口语理解数据生成流水线Thai-SUP。实验结果表明,该方案有效提升了泰语的自动语音识别和多任务理解能力,为低资源语言的SLLMs构建提供了新路径。
完成下面两步后,将自动完成登录并继续当前操作。