
ICASSP 2026|迈向构建低资源语种的多任务语音理解模型
内容提要
本文提出了一种针对低资源语言(如泰语)的语音大语言模型(SLLM)多任务理解方案,核心创新包括自监督学习的语音编码器XLSR-Thai、通用语音-文本对齐方法U-Align,以及泰语口语理解数据生成流水线Thai-SUP。实验结果表明,该方案有效提升了泰语的自动语音识别和多任务理解能力,为低资源语言的SLLMs构建提供了新路径。
关键要点
-
提出了一种针对低资源语言泰语的语音大语言模型多任务理解方案。
-
核心创新包括自监督学习的语音编码器XLSR-Thai、通用语音-文本对齐方法U-Align和泰语口语理解数据生成流水线Thai-SUP。
-
现有语音编码器在低资源语言上表现欠佳,难以支撑多任务理解。
-
U-Align方法大幅降低计算成本,提升多任务适配性。
-
Thai-SUP流水线生成超过1073小时的泰语口语理解数据集,覆盖意图分类、命名实体识别和语音改写任务。
-
实验结果表明,XLSR-Thai有效提升了泰语的自动语音识别和多任务理解能力。
-
U-Align方法在多任务理解中表现优于传统的ASR对齐方法,具备更高的有效性与高效性。
-
提出的方案为低资源语言构建高性能多任务理解的SLLMs提供了新路径。
延伸解读
低资源语言的挑战与机遇
低资源语言如泰语在语音识别和理解方面面临诸多挑战,主要是缺乏足够的标注数据和有效的模型支持。本文提出的方案通过自监督学习和数据生成技术,为这些语言的多任务理解提供了新的解决思路,展示了在技术创新下,低资源语言的潜力和发展机会。
U-Align方法的优势
U-Align方法在语音-文本对齐中表现出色,相较于传统的ASR对齐方法,能够在更低的计算成本下实现更高的任务精度。这一创新不仅提升了多任务理解的效率,也为其他低资源语言的模型构建提供了可借鉴的经验,具有广泛的应用前景。
泰语口语理解数据的生成
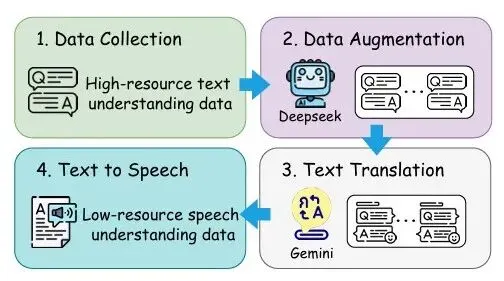
Thai-SUP流水线的构建解决了泰语口语理解数据稀缺的问题,通过高资源语言的数据迁移和生成,成功创建了超过1073小时的泰语口语理解数据集。这一数据集的丰富性将极大推动泰语及其他低资源语言的研究和应用,值得关注。
延伸问答
什么是XLSR-Thai语音编码器?
XLSR-Thai是首个针对泰语的自监督学习语音编码器,通过对大量泰语无标注语音进行预训练,提升了泰语的语音表征能力。
U-Align方法的优势是什么?
U-Align方法通过直接将适配后的语音表征与文本嵌入对齐,大幅降低计算成本,并提升多任务适配性,相较于传统的ASR对齐方法更有效。
Thai-SUP数据生成流水线的作用是什么?
Thai-SUP流水线用于生成泰语口语理解数据,通过高资源语言的文本数据迁移,解决低资源语言数据稀缺的问题。
该研究如何提升泰语的自动语音识别能力?
通过使用XLSR-Thai编码器和U-Align方法,该研究有效提升了泰语的自动语音识别性能,实验结果显示其表现优于传统方法。
低资源语言的多任务理解面临哪些挑战?
低资源语言的多任务理解面临语音编码器性能不足、语音-文本对齐计算成本高和标注数据稀缺等三大挑战。
实验结果如何验证XLSR-Thai的有效性?
实验结果表明,XLSR-Thai在ASR单任务和多任务理解上均优于原始XLSR模型,显示出其在泰语处理上的有效性。
