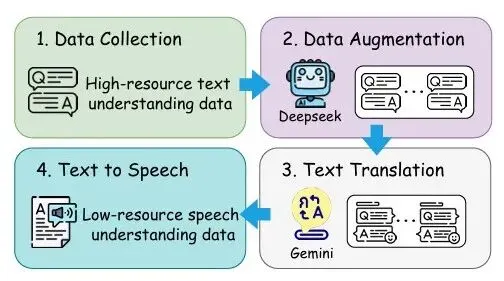
本文提出了一种针对低资源语言(如泰语)的语音大语言模型(SLLM)多任务理解方案,核心创新包括自监督学习的语音编码器XLSR-Thai、通用语音-文本对齐方法U-Align,以及泰语口语理解数据生成流水线Thai-SUP。实验结果表明,该方案有效提升了泰语的自动语音识别和多任务理解能力,为低资源语言的SLLMs构建提供了新路径。
谷歌发布了基于Gemma 3架构的开源翻译模型套件TranslateGemma,支持55种语言,提供4B、12B和27B三种参数规模,适用于移动设备和云加速器。通过监督微调和强化学习,TranslateGemma在翻译质量和效率上有显著提升,尤其在低资源语言方面表现优异,受到社区的赞赏,适合成本敏感的应用场景。
Hugging Face发布了FineTranslations数据集,包含超过1万亿个平行文本标记,涵盖英语及500多种语言,旨在改善机器翻译,尤其是英语到低资源语言的翻译。数据集来源于FineWeb2,经过严格筛选和处理,确保质量,可通过Hugging Face访问,支持大规模处理。
本文探讨了信息检索领域的最新研究进展,重点包括多语言检索、跨域推荐和合成数据生成。研究者们针对低资源语言开发了优化模型,提升了多模态信息检索的有效性,并提出了合成查询生成框架,以应对标注数据的不足。这些创新提高了信息检索的效率和准确性。
本研究提出了一种新方法DeFT-X,旨在解决高资源语言模型在低资源语言迁移中的挑战。通过去噪处理改进稀疏微调策略,提升了情感分类和自然语言推理任务的效果。
本研究提出了一种新的奖励建模方法,旨在解决深度推理模型在低资源语言翻译中的不足。与大型推理模型相比,该方法在文学翻译中表现出色,并成功扩展至11种语言,实现了90个翻译方向的优异性能。
本研究分析了大语言模型在多语言推理中的表现,发现英语推理模型在高资源语言中能有效提升跨语言数学推理能力,但低资源语言存在局限性。
本研究系统性回顾了生成语言建模中低资源语言的数据稀缺问题,评估了54项研究提出的技术策略,如单语数据增强和多语言训练。发现现有方法主要集中于少数低资源语言,评估方法不一致,并提出了扩展建议以支持更多低资源语言的生成模型构建。
本研究探讨了大型语言模型(LLMs)在非英语教育环境中的表现偏差,发现其在低资源语言上的效果较差,且与训练数据量相关。因此,在实际应用前需验证模型在目标语言的表现,以为教育领域的多语言应用提供实证依据和建议。
本研究提出了Compass-v2,一种轻量级混合专家模型,旨在提升东南亚低资源语言和电子商务领域的模型性能。通过构建高质量数据集,该模型在多语言和电子商务应用中表现优异,并降低了推理成本。
本研究提出了一种新方法,解决低资源语言在语音合成中的数据不足和复杂性问题。该方法结合数据优化框架和先进声学模型,支持零样本语音克隆,提升了在金融、医疗等领域的应用表现。
本研究探讨如何利用大型语言模型提升低资源语言的机器翻译,分析了示例提示、跨语言迁移和微调等技术,并比较了大型语言模型与传统模型的优缺点。
本研究提出了一种名为RoSPrompt的方法,旨在提升小型多语言预训练模型在低资源语言中的零样本分类性能。该方法有效解决了数据依赖性问题,增强了模型在数据分布变化时的泛化能力。实验结果表明,该方法在106种语言的数据集中表现优异。
本研究提出了一种框架,用于自动评估大型语言模型在低资源语言中的脆弱性。研究发现,尽管模型表现不佳,但风险较小,主要源于模型的无效反应。
本研究针对30多种低资源语言的情感检测,填补了该领域的空白。通过多条赛道的情感标签预测,提供基线结果和最佳系统表现,为多语言情感分析提供重要参考,推动跨语言情感检测的发展。
本研究探讨了跨语言IPA对比学习在低资源语言零样本命名实体识别中的应用。通过减少相似语音特征语言间的IPA差距,提出的CONLIPA数据集和IPAC方法显著提升了识别性能,展示了其应用潜力。
本研究提出LLM-C3MOD系统,旨在改善低资源语言中仇恨言论管理的文化理解不足问题。通过增强文化背景注释和人工管理,该系统提高了分析准确性,减轻了人类调节者的工作量。研究表明,适当支持的非母语调节者能够有效参与跨文化仇恨言论管理。
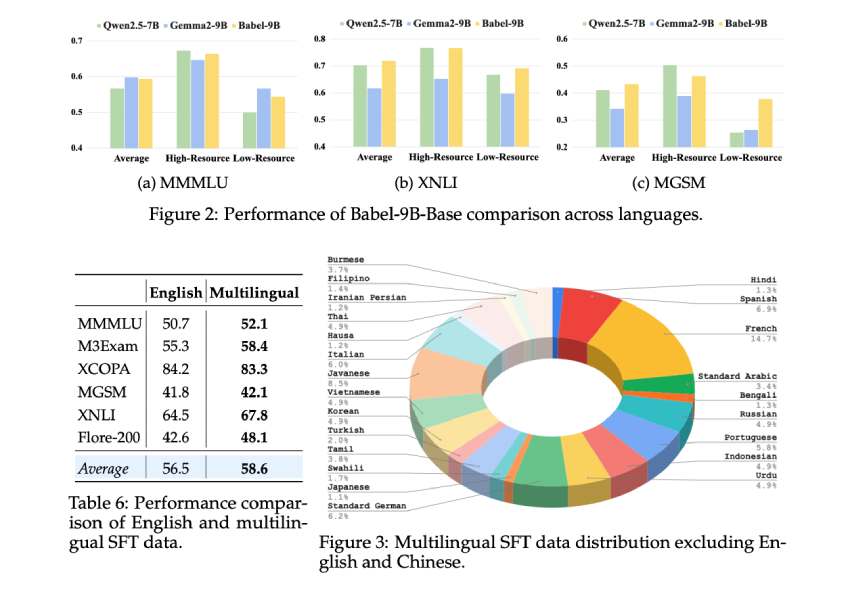
阿里巴巴的Babel模型通过层扩展技术,支持25种语言,提升了低资源语言的处理能力。Babel-9B和Babel-83B在多语言任务中表现优异,尤其在推理和翻译方面,提高了训练数据有限语言的准确性。
本研究探讨大型语言模型在不同语言中学习新知识的不平等现象,发现低资源语言在有效性、可迁移性、优先级和鲁棒性等方面普遍处于劣势,旨在提高对语言不平等的认识,推动更公平的LLMs发展。
本研究针对低资源语言在词义消歧义(WSD)和词义引导(WSI)任务中缺乏大型数据集的问题,提出利用生成的句子对和字典示例来有效区分词义。结果显示,该方法在WSD和WSI任务上优于现有模型,显著提升了低资源语言的处理能力。
完成下面两步后,将自动完成登录并继续当前操作。