
阿里发布 Babel:开放多语言大型语言模型 LLM 服务全球 90% 以上使用者
内容提要
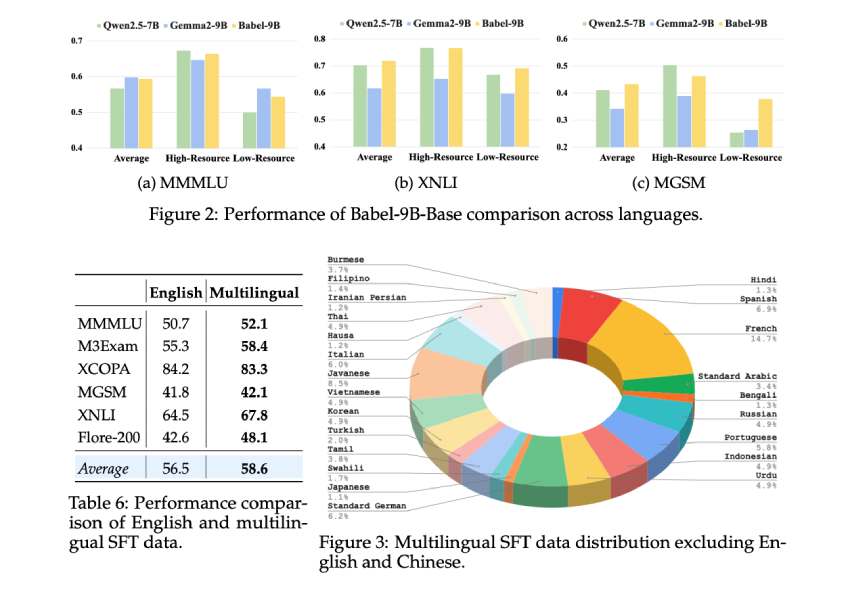
阿里巴巴的Babel模型通过层扩展技术,支持25种语言,提升了低资源语言的处理能力。Babel-9B和Babel-83B在多语言任务中表现优异,尤其在推理和翻译方面,提高了训练数据有限语言的准确性。
关键要点
-
阿里巴巴的Babel模型通过层扩展技术,支持25种语言,提升了低资源语言的处理能力。
-
现有的多语言LLM模型优先考虑资源丰富的语言,导致低资源语言的处理能力不足。
-
Babel模型采用结构化层扩展方法,避免了传统预训练的高计算需求。
-
Babel-9B和Babel-83B在推理和翻译任务中表现优异,分别取得63.4和73.2的平均分。
-
Babel显著提高了训练数据有限语言的准确性,尤其在代表性不足的语言中表现提高了5-10%。
-
监督微调(SFT)模型在超过100万个对话数据集上训练,性能可与商业AI模型相媲美。
-
研究团队强调进一步增强可以提升Babel的功能,使其成为更强大的多语言AI工具。
延伸解读
多语言模型的挑战与机遇
当前多语言模型普遍面临资源分布不均的问题,许多低资源语言的处理能力不足。阿里巴巴的Babel模型通过创新的层扩展技术,显著提升了这些语言的准确性,为全球用户提供了更公平的语言处理解决方案。
Babel模型的技术优势
Babel模型采用结构化层扩展方法,避免了传统预训练的高计算需求。这种设计使得模型在保持高性能的同时,能够更高效地处理多种语言,尤其是那些训练数据有限的语言,展现出更强的适应性。
性能评估与市场竞争
Babel-9B和Babel-83B在多语言基准测试中表现优异,分别取得63.4和73.2的平均分,超越了多款竞争对手。这表明Babel在多语言处理领域的潜力,可能会对现有市场格局产生影响。
延伸问答
Babel模型支持哪些语言?
Babel模型支持25种语言,覆盖全球90%以上的使用者。
Babel模型如何提高低资源语言的处理能力?
Babel通过层扩展技术和优化数据质量,显著提高了低资源语言的准确性。
Babel-9B和Babel-83B的性能如何?
Babel-9B在多语言基准测试中平均得分为63.4,Babel-83B则达到73.2,表现优异。
Babel模型的训练数据来源是什么?
Babel的训练数据来自维基百科、新闻文章、教科书和多语言语料库等多个来源。
Babel模型与其他多语言模型相比有什么优势?
Babel在处理低资源语言方面表现提高了5-10%,并且在推理和翻译任务中优于其他模型。
监督微调(SFT)在Babel模型中起什么作用?
监督微调使Babel在超过100万个对话数据集上训练,提升了其在多语言讨论中的性能。
