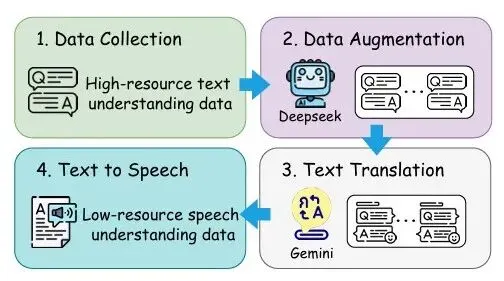
本文提出了一种针对低资源语言(如泰语)的语音大语言模型(SLLM)多任务理解方案,核心创新包括自监督学习的语音编码器XLSR-Thai、通用语音-文本对齐方法U-Align,以及泰语口语理解数据生成流水线Thai-SUP。实验结果表明,该方案有效提升了泰语的自动语音识别和多任务理解能力,为低资源语言的SLLMs构建提供了新路径。
PaddleOCR 3.2版本发布,英文文本识别精度提升近11%,新增泰语和希腊语支持。全面升级C++本地部署能力,提供高稳定性服务化部署方案,并支持细粒度性能基准测试,帮助用户优化部署。
本研究提出了开放的泰语推理模型Typhoon T1,解决了低资源语言推理模型开发中的细节不足问题,并通过监督微调方法提升了链式推理能力。
本研究提出了一种模型融合方法,显著提升了泰语大型语言模型的推理能力,达到DeepSeek R1水平。
本研究针对泰语大型语言模型的不足,推出了优化的文本、视觉和音频模型,通过开放模型和混合数据进行预训练,显著提升了泰语的表现,对信息处理和多模态理解产生深远影响。
本研究创建了一个包含7200张图像的泰语手语手指拼写数据集,以解决数据不足问题,推动手势识别技术的发展,促进深度学习和计算机视觉的应用。
本文研究了大型语言模型在多语言机器翻译中的优势与挑战,评估了多种模型在102种语言上的表现。研究发现,大型模型在翻译能力上有所进展,但在特定任务中,简单模型表现更佳。通过微调和训练,低资源语言的翻译能力也有所提升,强调了参考翻译和提示技术的重要性,为未来的多语言翻译研究提供了新视角。
本文介绍了新的孟加拉语数据集BenCoref,评估了多种模型在指代消解任务中的表现,强调了特定语言资源的需求,并探讨了跨语言和多语种指代解析的挑战与进展。
本文探讨了无监督学习在常识推理中的应用,特别是针对Winograd Schema Challenge的研究。通过对大量未标记数据的训练,提出了新的评估方法和基准,分析了现有基准的局限性,并展示了预训练语言模型在多语言环境中的有效性。研究表明,尽管模型表现有所提升,但仍存在对人类理解的敏感性差异。
本文介绍了从维基百科数据中创建特定语言BERT模型的自动化流程,并引入了42个新的模型。评估结果显示,这些特定语言模型在某些语言方面有显著改进。初步结果为了解特定语言模型的最佳条件提供了第一步。
完成下面两步后,将自动完成登录并继续当前操作。