ChatGPT升级的语音模式更擅长保持安静
The Verge
·

推出GPT-Live
OpenAI
·

OpenAI将GPT-5级推理引入其语音模型
The New Stack
·
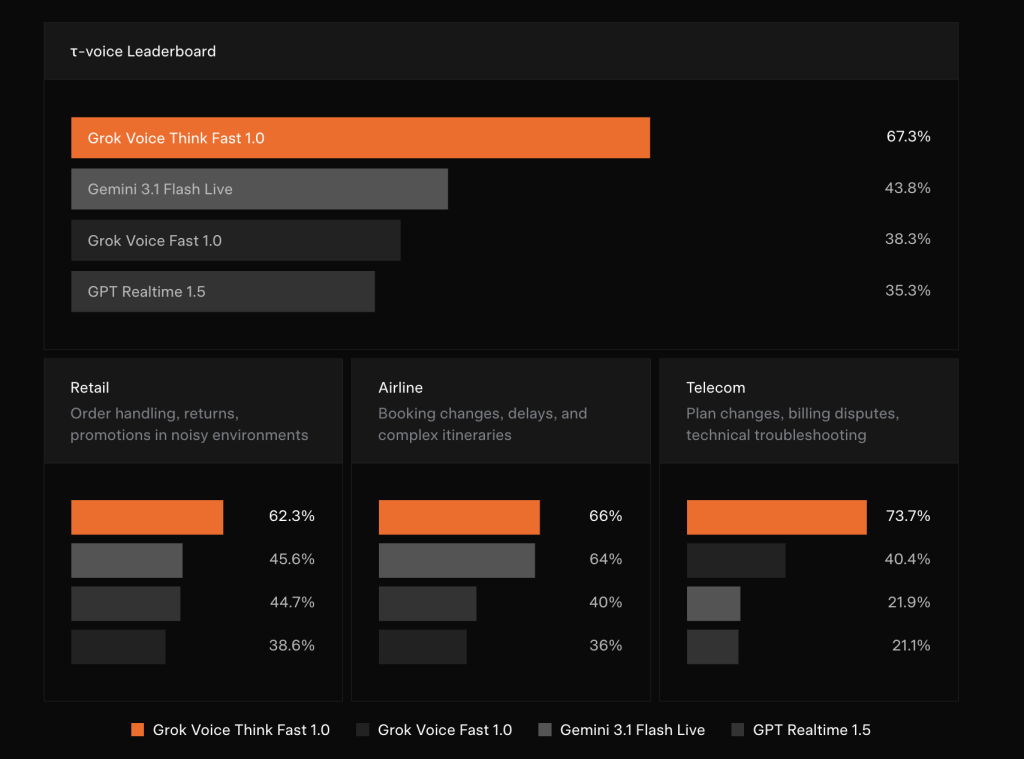
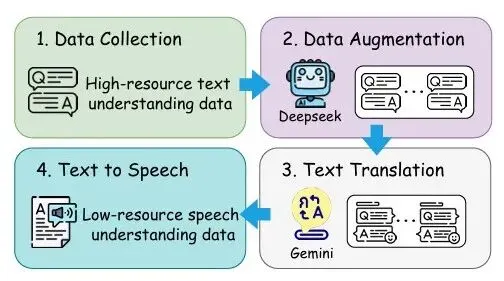
ICASSP 2026|迈向构建低资源语种的多任务语音理解模型
实时互动网
·

针对哪种模型的评估?语音模型评估的分类法
Apple Machine Learning Research
·