
Miso Labs发布MisoTTS:一款拥有开放权重的80亿情感文本转语音模型
内容提要
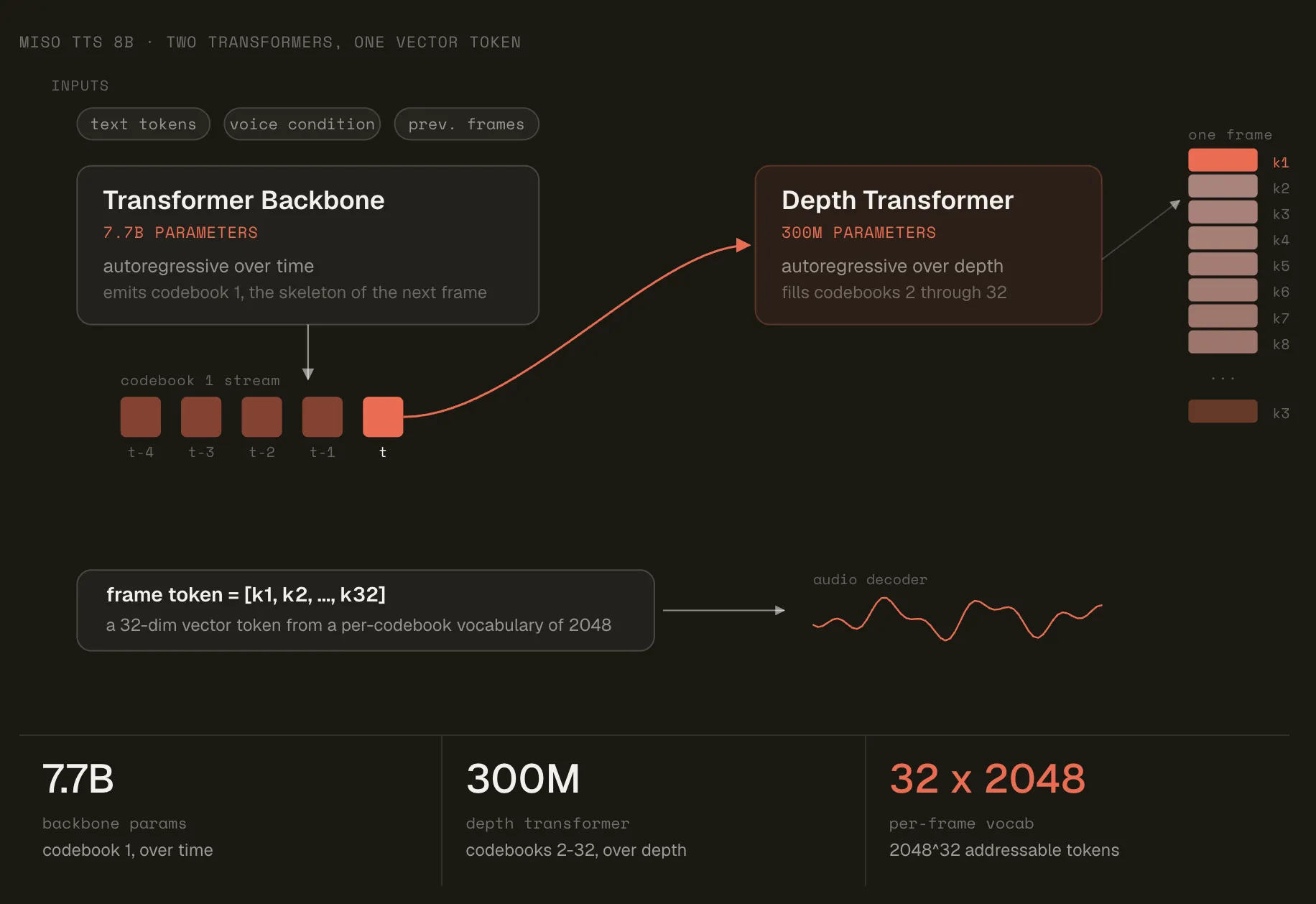
Miso Labs发布了MisoTTS,这是一款拥有80亿参数的文本转语音模型,采用残差矢量量化技术,能够根据文本和音频上下文生成富有表现力的语音。该模型的词汇量可扩展至约2048³²,支持半双工传输,API访问正在开发中。
关键要点
-
Miso Labs 发布了 MisoTTS,这是一款开放权重、拥有 80 亿参数的文本转语音模型。
-
MisoTTS 能够根据文本和音频上下文生成富有表现力的语音,采用残差矢量量化 (RVQ) 技术。
-
该模型的词汇量可扩展至约 2048³²,支持半双工传输。
-
MisoTTS 的骨干网为 77 亿参数的 Transformer 模型,解码器为 3 亿参数的模型。
-
API 访问正在开发中,当前仅支持半独立式住宅的传输方式。
延伸解读
技术创新与应用前景
MisoTTS采用的残差矢量量化技术(RVQ)为文本转语音领域带来了新的可能性。通过扩展词汇量而不增加参数,模型能够更好地捕捉人类语音的多样性。这种技术的应用不仅限于语音合成,还可能在虚拟助手、游戏角色对话等场景中发挥重要作用。
市场竞争与挑战
MisoTTS在延迟方面表现优异,声称为110毫秒,远低于竞争对手。然而,当前仅支持半双工传输,这限制了其在实时对话中的应用。未来,如何提升API的可用性和扩展性,将是Miso Labs面临的重要挑战。
开放性与社区影响
Miso Labs选择在修改后的MIT许可证下开源MisoTTS,这将促进开发者社区的参与和创新。开放权重的策略可能吸引更多研究者和开发者进行二次开发,推动文本转语音技术的进一步发展。
延伸问答
MisoTTS是什么类型的模型?
MisoTTS是一款拥有80亿参数的文本转语音模型,采用开放权重设计。
MisoTTS如何生成语音?
MisoTTS根据文本和音频上下文生成富有表现力的语音,使用残差矢量量化技术。
MisoTTS的词汇量有多大?
MisoTTS的词汇量可扩展至约2048³²,支持丰富的音频表达。
MisoTTS的延迟表现如何?
MisoTTS的延迟为110毫秒,相比于竞争对手有明显优势。
MisoTTS的API访问情况如何?
MisoTTS的API访问正在开发中,目前尚未开放。
MisoTTS的主要优势是什么?
MisoTTS的优势包括开放源代码、扩展音频范围和对音频上下文的依赖。
