
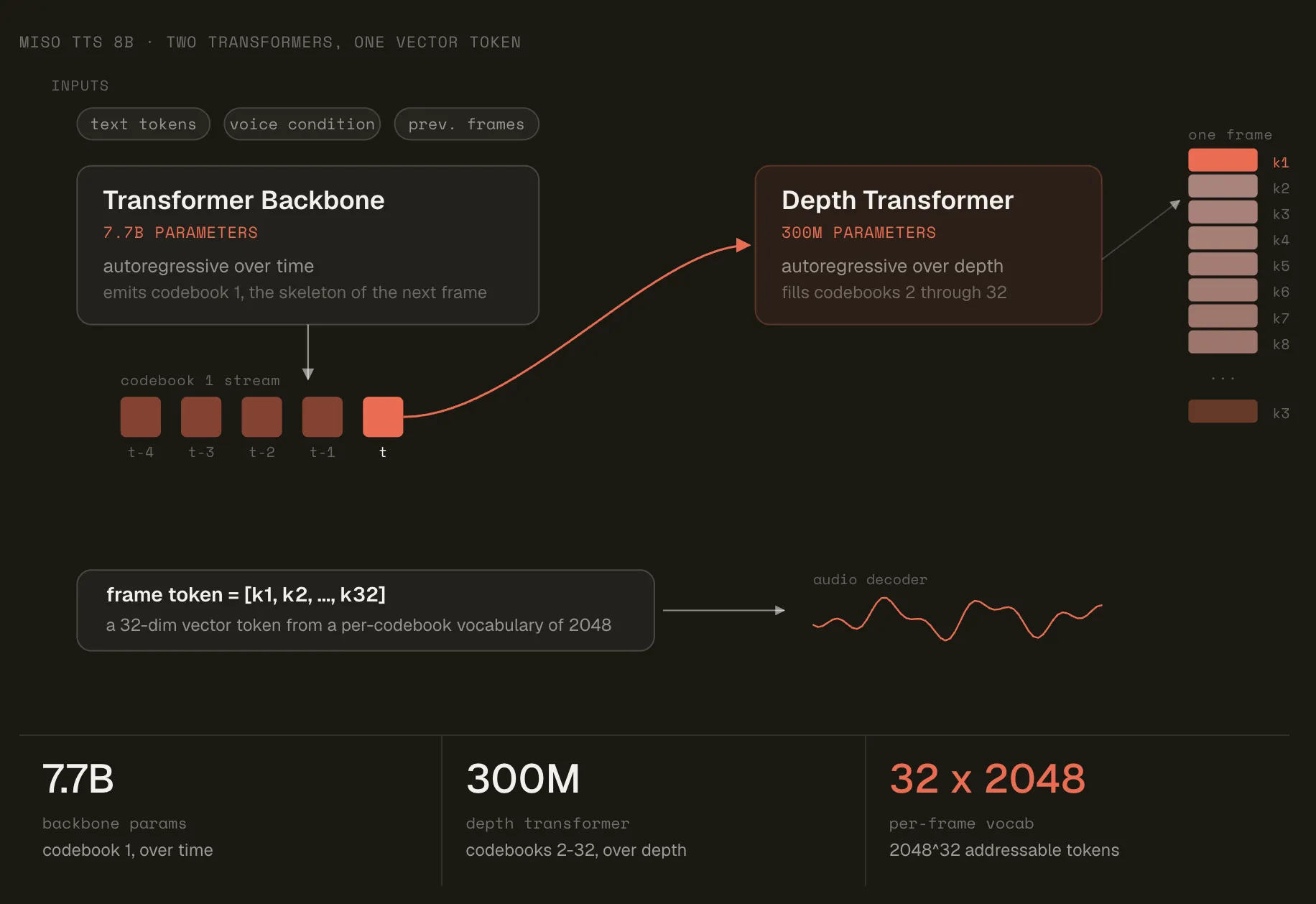



用于语音推测解码的原则性粗粒度接受
Apple Machine Learning Research
·

Visatronic:一种用于语音合成的多模态解码器模型
Apple Machine Learning Research
·

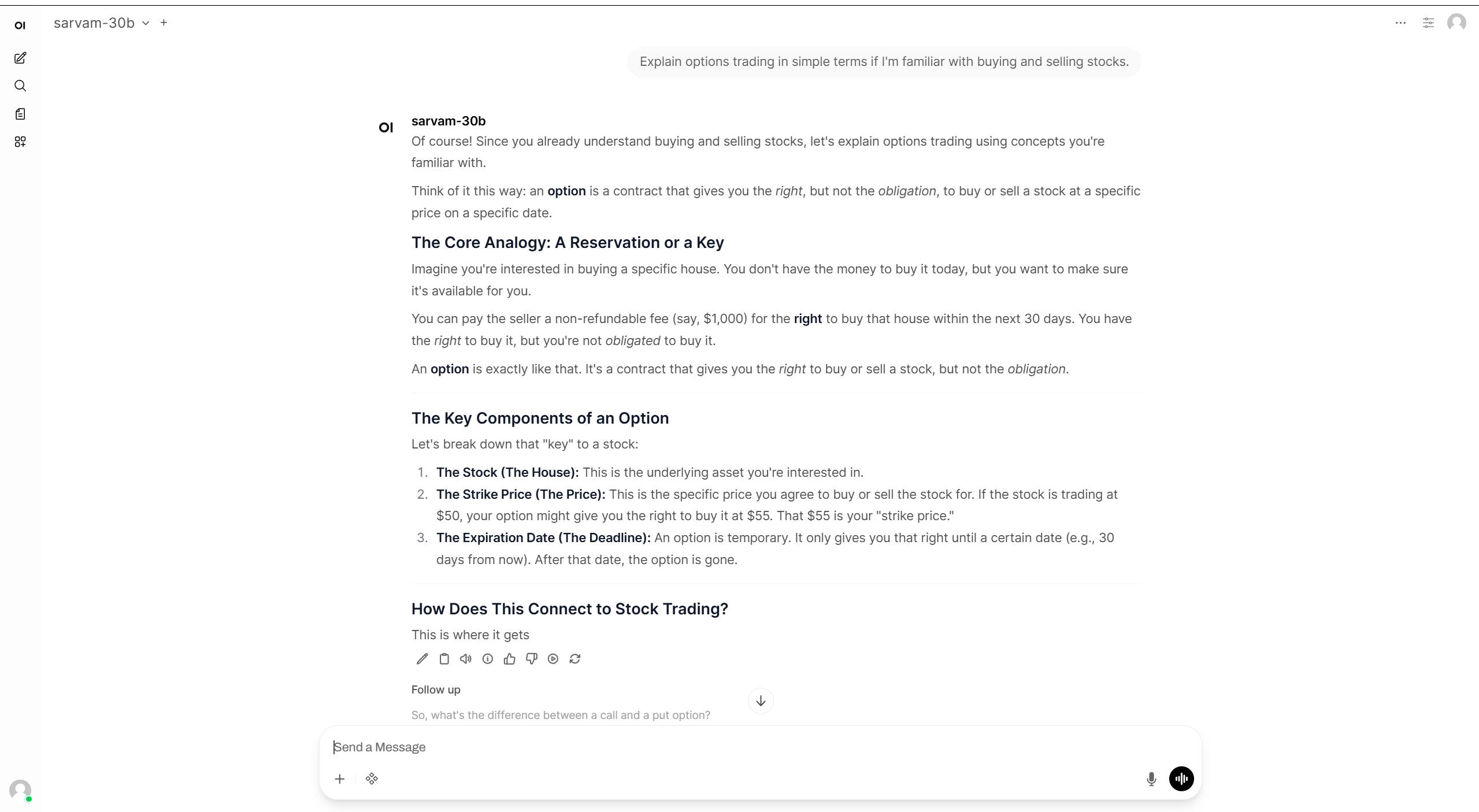
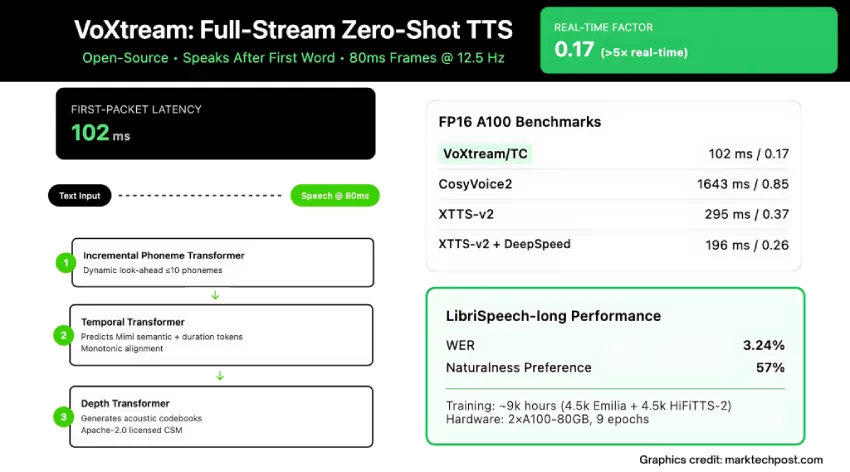
从MCP到多代理:当前GitHub上最重要的10个新开源AI项目及其意义
The GitHub Blog
·


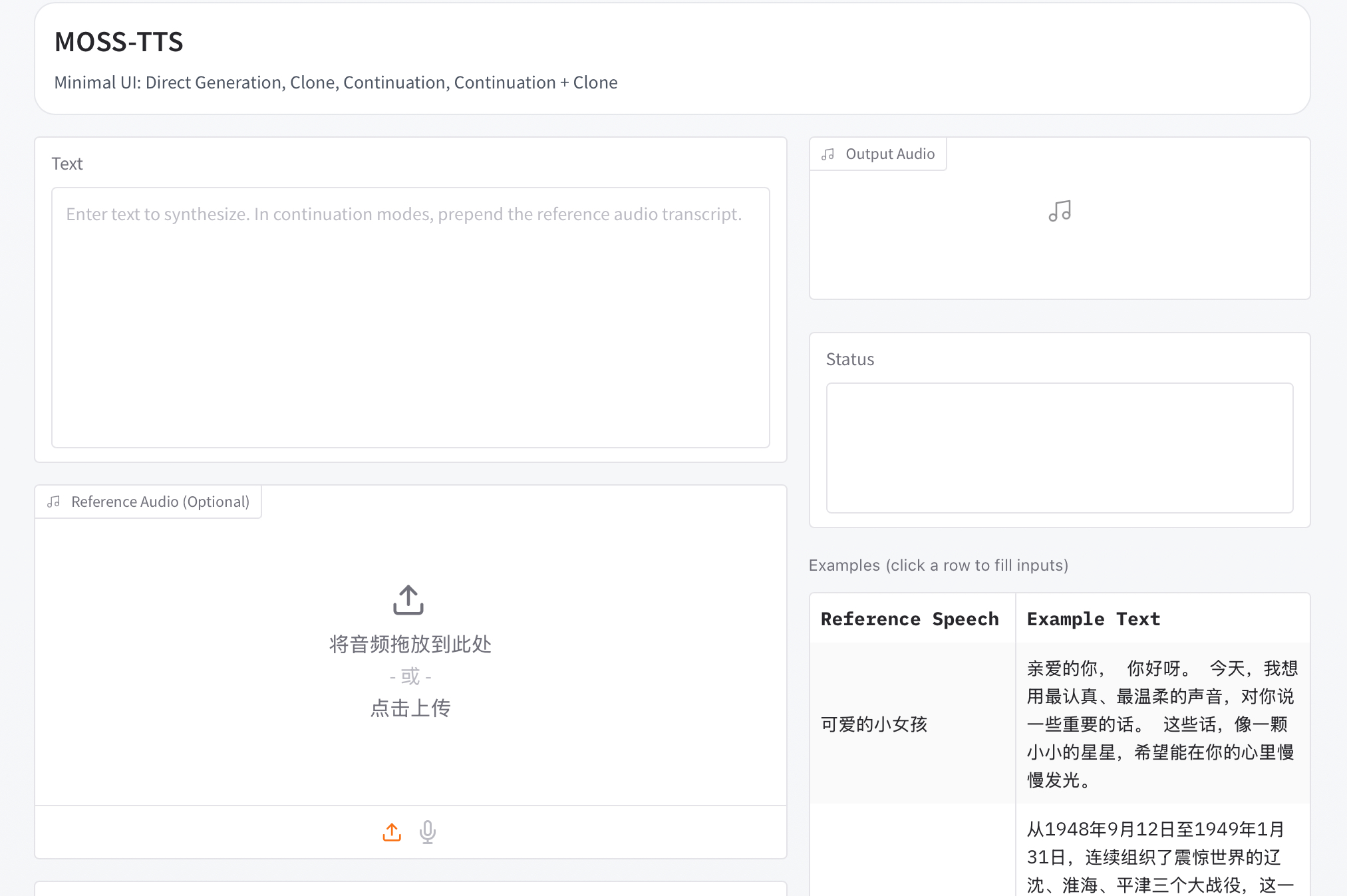
Qwen2.5 Omni: See, Hear, Talk, Write, Do It All!
Blog on Qwen
·
