
VoXtream:一款开源的全流式零样本文本转语音模型,支持实时应用
内容提要
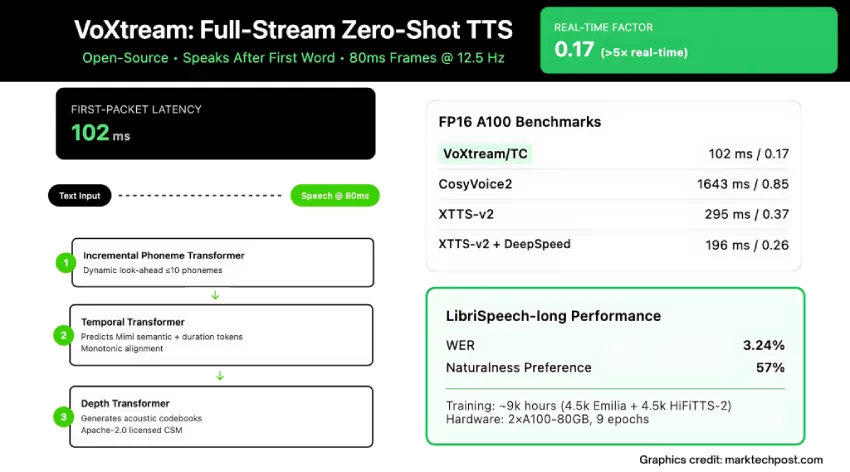
VoXtream技术通过实时文本处理消除了传统TTS系统的延迟,采用动态音素前瞻机制,提升了语音生成的速度和自然度。与其他系统相比,VoXtream在字错误率和实时因子上表现优异,适合实时语音代理和同声传译。
关键要点
-
VoXtream技术通过实时文本处理消除了传统TTS系统的延迟。
-
VoXtream采用动态音素前瞻机制,提升了语音生成的速度和自然度。
-
VoXtream在字错误率和实时因子上表现优异,适合实时语音代理和同声传译。
-
VoXtream在首个单词后即刻发声,输出音频的帧时间为80毫秒。
-
全流式TTS系统实时处理文本并同步输出音频,消除了输入端缓冲。
-
增量式音素转换器(PT)内部的动态音素前瞻机制是VoXtream的核心技巧。
-
VoXtream采用单一全自回归(AR)管道,包含音素转换器、时间变换器和深度变换器。
-
VoXtream在多个基准测试中表现出色,字错误率低于CosyVoice2。
-
VoXtream的实时因子在编译后运行速度比实时速度快5倍以上。
-
VoXtream在9000小时的中型语料库上进行训练,确保核心质量指标稳定。
-
VoXtream被定位于近期交错式AR + NAR声码器方法和LM编解码器堆栈之中。
延伸解读
VoXtream的实时优势
VoXtream技术通过实时文本处理,显著降低了传统TTS系统的延迟,使得语音生成几乎无缝对接。这一特性使其在实时语音代理和同声传译等应用中具有明显优势,能够提升用户体验,尤其是在需要快速反应的场景中。
动态音素前瞻机制的核心作用
VoXtream的动态音素前瞻机制允许系统在接收到首个词后立即开始发声,而无需等待完整的上下文。这种设计不仅减少了起始延迟,还提高了语音生成的自然度,适合需要即时反馈的应用场景。
与其他系统的比较
在字错误率和实时因子方面,VoXtream的表现优于CosyVoice2等其他流式TTS系统。这表明VoXtream在处理实时语音时,能够提供更高的准确性和更快的响应速度,适合对语音质量和实时性要求较高的应用。
延伸问答
VoXtream技术如何消除传统TTS系统的延迟?
VoXtream通过实时文本处理,在首个单词后即刻发声,输出音频的帧时间为80毫秒,从而消除了传统TTS系统的延迟。
VoXtream的动态音素前瞻机制有什么作用?
动态音素前瞻机制允许增量式音素转换器在不等待完整上下文的情况下,最多预览10个音素,以稳定韵律并快速生成语音。
VoXtream在字错误率方面的表现如何?
VoXtream在多个基准测试中表现优异,字错误率低于CosyVoice2,达到3.24%。
VoXtream适合哪些应用场景?
VoXtream适合实时语音代理、现场配音和同声传译等需要低延迟的应用场景。
VoXtream的实时因子表现如何?
VoXtream的实时因子在编译后运行速度比实时速度快5倍以上,显示出其高效性。
VoXtream的训练数据集有多大?
VoXtream在9000小时的中型语料库上进行训练,确保核心质量指标的稳定。
