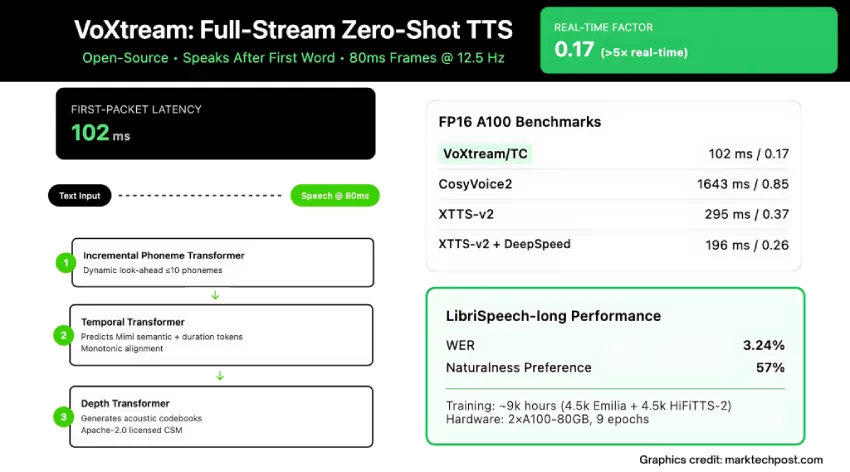
VoXtream技术通过实时文本处理消除了传统TTS系统的延迟,采用动态音素前瞻机制,提升了语音生成的速度和自然度。与其他系统相比,VoXtream在字错误率和实时因子上表现优异,适合实时语音代理和同声传译。
魅族推出全新AI眼镜StarV Snap,售价1999元,重39克。支持12国语言同声传译、AI识物、语音转写和扫码支付,配备1200万像素镜头,支持720P录制和1080P拍摄,适合内容创作者和Vlog爱好者。
雷登A7蓝牙耳机支持同声传译,设计轻巧,音质优良,续航达50小时,防水等级IPX4,适合运动和日常使用,价格在百元左右,值得尝试。
火山引擎发布豆包系列新模型,包括图像编辑模型3.0和同声传译模型2.0,提升了指令遵循和语音延迟,支持多模态检索,并推出开源开发工具和模型托管方案,助力企业AI应用落地。
火山引擎推出的豆包·同声传译模型Seed LiveInterpret 2.0,支持中英同传,延迟仅2-3秒,无需样本即可复刻音色,适合国际会议和日常交流,提升跨语言沟通体验。
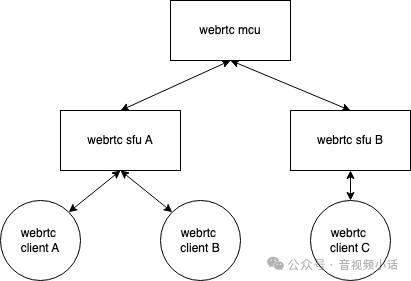
本文介绍如何利用AI技术为WebRTC视频会议实时生成字幕,提升会议体验。通过音频流处理、语音活动检测和语音转文字技术,实现实时字幕功能,未来可实现同声传译。
字节跳动在深圳的巡展上发布了多模态大模型,包括视频生成、音乐生成和同声传译。豆包视频模型通过DiT架构实现动态生成和多镜头切换,支持多种风格。音乐模型可通过文本或图片生成音乐,并支持风格转换。同声传译模型实现实时翻译。火山引擎还升级了现有模型,提高了效率和性能,降低了成本。
本文探讨了同声传译中的自动语音翻译系统,比较了人类译员与机器翻译的差异,并提出利用大型语言模型(LLMs)进行实时翻译的新方法。研究表明,该方法在翻译质量和延迟方面具有优势,为多语言交流的民主化提供了新思路。同时,介绍了多语言语音文本翻译模型的开发及其性能提升。
字节跳动的研究人员推出了端到端同声传译智能体CLASI,效果接近专业人工水平。CLASI采用了端到端架构,具备获取外部知识的能力。在人工评测中,CLASI超过商业系统和开源SOTA系统,甚至达到或超过人类同传水平。研究人员还引入了多模态检索增强生成过程,提高了翻译质量。
完成下面两步后,将自动完成登录并继续当前操作。